Active Directory is also LDAP. So to integrate with the Active Directory you can use code very similar to that one used with other LDAP servers.
To connect to the Active Directory you can do something like this:
import java.util.Hashtable;
import
javax.naming.Context;
import
javax.naming.NamingException;
import
javax.naming.directory.DirContext;
import
javax.naming.directory.InitialDirContext;
/**
* @author mrojas
*/
public class Test1
{
public static void main(String[] args)
{
Hashtable
environment = new Hashtable();
//Just
change your user here
String
myUser = "myUser";
//Just change your user password here
String
myPassword = "myUser";
//Just
change your domain name here
String
myDomain = "myDomain";
//Host
name or IP
String
myActiveDirectoryServer = "192.168.0.20";
environment.put(Context.INITIAL_CONTEXT_FACTORY,
"com.sun.jndi.ldap.LdapCtxFactory");
environment.put(Context.PROVIDER_URL,
"ldap://" + myActiveDirectoryServer
+ ":389");
environment.put(Context.SECURITY_AUTHENTICATION,
"simple");
environment.put(Context.SECURITY_PRINCIPAL,
"CN=" + myUser + ",CN=Users,DC=" + myDomain + ",DC=COM");
environment.put(Context.SECURITY_CREDENTIALS,
myPassword);
try
{
DirContext context = new InitialDirContext(environment);
System.out.println("Lluvia de exitos!!");
}
catch
(NamingException e)
{
e.printStackTrace();
}
}
}
These days I have been testing all of our 64-bit labs on a
Montecito (Itanium) box that was lent to use by HP. The newest feature of
this new chip is the fact that it has two cores, which should make
multi-threaded applications perform a lot faster. I have not developed in
a while for the Itanium, and one of the first things that struck me was the
fact that there is no "Intel Compiler Installer" available for download.
As of version 9.1.028, the compiler installer includes compilers for x86, x64,
and IA64 - sweet.
While following my usual install procedure (click next until the installer
finishes) I noticed that my IA64 compiler was completely broken - even when
compiling a Hello World. The error I got was the following:
icl: internal error: Assertion failed (shared/driver/drvutils.c, line 535)
After reading some forums which did not hint me at all what the problem was, I
decided to re-install but this time around reading the installer
screens. It happens that one of the requirements for this compiler
to work is that it needs the PSDK from Microsoft installed, something that I
had completely forgotten to do. Once I installed the PSDK, the IA64
compiler was a happy camper and everything worked OK. Hopefully, some
desperate soul will be able to find this info if they ever face that dreaded
message.
How do we appropriately represent Web pages for semantic analysis and particularly for refactoring purposes? In a previous post at this same place, we introduced some of the main principles of what we have called semantically driven rational refactoring of Web pages as a general framework of symbolic reasoning. At this post, we want to develop some preliminary but formally appealing refinement concerning page representation; we assume our previous post has been read and we put ourselves in its context: development of automated tools pointing to the task of refactoring as a goal.
We claim that many valuable derivations can be obtained by following a semantic approach to the handling of web pages those of which are both of conceptual and implementation nature and interest; we believe looking with more detail at such derivations may provide us with more evidence for sustaining our claim on semantics in the context of refactoring. In this post, we want to consider one very specific case of conceptual derivation with respect to the representation model. Specifically, we want to present some intuitive criteria for analyzing theoretically a symbolic interpretation of the popular k-means clustering scheme, which is considered useful for the domain of web pages in more general contexts.
Let us first and briefly remain why that is relevant to refactoring, to set up a general context. We recall that refactoring is often related to code understanding; hence building a useful semantic classification of data, in general, is a first step in the right direction. In our case web pages are our data sources, we want to be able to induce semantic patterns inside this kind of software elements, in a similar way as search engines do to classify pages (however, we had to expect that specific semantic criteria are probably being more involving in our refactoring case where, for instance, procedural and implementation features are especially relevant; we will expose such criteria in future posts).
In any case, it is natural to consider clustering of pages according to some given semantic criteria as an important piece in our refactoring context: Clustering is essence about (dis)similarity between data, is consequently very important in relation to common refactoring operations, especially those ones aiming at code redundancy. For instance, two similar code snippets in some set of web pages may become clustered together, allowing by this way an abstraction and refactoring of a "web control" or similar reusable element.
As several authors have done in other contexts, we may use a symbolic representation model of a page; in a general fashion pages can naturally be represented by means of so-called symbolic objects. For instance, an initial approximation of a page (in an XML notion) can be something of the form given below (where relevant page attributes (or features) like "title" and "content" can be directly extracted from the HTML):
<rawPage
title="Artinsoft home page"
content="ArtinSoft, the industry leader in legacy application migration and software upgrade technologies, provides the simple path to .NET and Java from a broad range of languages and platforms, such as Informix 4GL and Visual Basic."
.../>
Because this representation is not as such effortless for calculation purposes, attribute values need to be scaled from plain text into a more structured basis, for clustering and other similar purposes. One way is to translate each attribute value in numerical frequencies (e.g. histogram) according to the relative uses of normalized keywords taken from a given vocabulary (like "software", "legacy", "java", "software", etc) by using standard NLP techniques. After scaling our page could be probably something similar to the following:
<scaledPage
title ="artinsoft:0.95; software:0.00; java:0.00; "
content="artinsoft:0.93; software:0.90; java:0.75; " .../>
The attribute groups values are denoting keywords and its relative frequency in page (data is hypothetic in this simple example), as usual. Notice the attribute group is another form of symbolic object whose values are already numbers. In fact, we may build another completely flat symbolic object where attribute values are all scalar, in an obvious way:
<flatPage
title.artinsoft="0.95" title.software="0.00" title.java="0.00"
content.artinsoft="0.93" content.software="0.90" content.java="0.75" .../>
Now pages that are by this way related to some common keywords set can be easily compared using some appropriate numerical distance. Of course, more complex and sophisticated representations are feasible, but numerically scaling the symbolic objects remains as an important need at some final stage of the calculation. However, and this is a key point, many important aspects of the computational process can be modeled independently of such final numerical representation (at the side of the eventual explosion of low-level attributes or poorly dense long vectors of flat representations, which are not the point here).
Let us develop more on that considering the k-means clustering scheme but without committing it to any specific numerically valued scale, at least not too early. That is, we want to keep the essence of the algorithm so that it works for "pure" symbolic objects. In a simplified way, a (hard) k-means procedure works as follows:
1.Given are a finite set of objects D and an integer parameter k.
2.Choose k objects from D representing the initial group of cluster leaders or centroids.
3.Assign each object in D to the group that has the closest centroid.
4.When all objects in D have been assigned, recalculate the k centroids.
5.Repeat Steps 2 and 3 until the centroids no longer change (move).
Essential parameters to the algorithm are 1) the distance function (of step 3) to compute the closest object and some form of operation allowing "object combination" in order to produce the centroids (step 4) (in the numerical case "combination" calculates the mean vector from vectors in cluster).
Such a combination needs to be "consistent" with the distance to assure the eventual termination (not necessarily global optimality). We pursue to state a formal criterion of consistency in an abstract way. Fundamental for assuring termination is that every assignment of one object X to a new cluster occurs with lower distance with respect to the new cluster leader than the distance to the previous clusters leaders of X. In other words the assignment of X must be a really new one. Combine operation after assignment (step 4) must guarantee that in every old cluster where X was, their leaders still remain more distant after future recalculations. So we need abstract definitions of distance and object combination would satisfy these invariant, that we call consistency.
To propose a distance is usually easier (in analogy to the vector model), objects are supposed to belong to some class and the feature values belong to some space or domain provided with a metric. For instance, an attribute like "title" takes values over a "String" domain where several numerical more o less useful metrics can possibly be defined. For more structured domains, built up from metric spaces, we may homomorphically compose individual metrics of parts for building the metric of the composed domain. For a very simplified example, if we have two "page" objects X and Y of the following form:
X= <page>
<title>DXT</title>
<content>DXC</content>
</page>
Y= <page>
<title>DYT</title>
<content>DYC</content>
</page>
Where we have that DXT and DYT are eventually complex elements representing symbolic objects over a metric domain DT provided with distance dist_DT and similarly DXC, DYC comes from a metric space DC with metric dist_DC. We may induce a metric dist_page for the domain “page”, as linear combination (where weights for dimensions could also be considered):
dist_page(X, Y) = dist_DT(DXT, DYT) + dist_DC(DXC, DYC)
Using the simple illustration, we see that we may proceed in a similar fashion for the combine_page operation, assuming operations combine_DT and combine_DC. In such a case, we have:
combine_page(X,Y)= <page>
<title>combine_DT(DXT,DYT)</title>
<content>combine_DC(DXC,DYC)</content>
</page>
It is straightforward to formulate the general case, the principle is simple enough. It is worth to mention that "combine" is clearly a kind of abstract unification operation; in general, we claim has to be consistent with the "distance" function (at every domain); further requirements rules this operation, in particular, that the domain needs to be combination-complete or combination-dense.
Proving consistency strongly relies on abstract properties like the following:
dist_D(X, Y) >= dist_D(combine_D(X,Y), Y)
In other words, that "combine" actually comprises according to distance. Fortunately, by using homomorphic compositions of consistent domains, we recover consistency at the composed domain. At the scalar level, for instance with numbers, using average as "combination" operation easily assures consistency.
This week I finally manage to sit down and start using the 1.0 release of PowerShell. So far I’m impressed with its capabilities and ease of use. Here are a couple of tips to get you started with PowerShell scripting:
Get-Help
The commands in PowerShell follow the format verb-noun. It is very easy to “guess” a command once you’ve been using PS for a little while. To get the processes on the system, for example, you use the command get-process. To get the contents of a file you use get-contents -path . An so on.
So, guess what command is used to get help? Too easy, isn’t it? get-help is your greatest ally when working with PowerShell. If you are unsure of what a command does or how it works, you just need to invoke the get-help command, followed by the name of the command:
PS C:\> get-help get-process
NAME
Get-Process
SYNOPSIS
Gets the processes that are running on the local computer.
…
Also, get-help supports wildcards, so you can use it to search for commands (in case you’re not 100% positive on the exact command name). So, for example, you can do a:
PS C:\> get-help get-*
Name Category Synopsis
---- -------- --------
Get-Command Cmdlet Gets basic information about cmdlets...
Get-Help Cmdlet Displays information about Windows P...
Get-History Cmdlet Gets a list of the commands entered ...
…
Script Security
PowerShell scripts have the extension *.ps1. To execute scripts, you need to do two things:
- Enable script execution. This is achieved with the command Set-ExecutionPolicy. To learn more about this command, you can type:
PS C:\> get-help set-executionPolicy
- Enter the path to the script. If it is in the local directory, enter .\.ps1. If not, enter the fully qualified path.
Scripting in PowerShell is very easy – the syntax is very C#-like, and it has the power of both the .NET Framework AND COM objects at your disposal.
Use .NET Data Types
PowerShell is built on top of the .NET Framework. Because of that, you can use .NET Data Types freely in your scripts and in the command prompt. You can do things like:
PS C:\> $date = new-object -typeName System.DateTime
PS C:\> $date.get_Date()
Monday, January 01, 0001 12:00:00 AM
Further help
Some great places to get you started with Powershell are:
Windows PowerShell Team blog
Technet’s PowerShell Scripting Center
Just PowerShell it
PowerShell For Fun
Don’t forget to get the Windows PowerShell Help Tool, for free, from Sapien’s website.
I found a super interesting blog called
Busy ColdFusion Developers' Guide to HSSF Features
http://www.d-ross.org/index.cfm?objectid=9C65ECEC-508B-E116-6F8A9F878188D7CA
HSSF is part of an open source java project that provides FREE OPEN SOURCE libraries to create Microsoft Office Files like Microsoft Word or Microsoft Excel.
So I was wondering could it be possible with Coldfusion to use those libraries. Specially now that Coldfusion MX relies heavily in Java. So I found this wonderfull blog that explains it all.
It just went to the HSSF download site:
http://www.apache.org/dyn/closer.cgi/jakarta/poi/
The project that holds these libraries is called POI.
When you enter in those links there is a release directory and a bin directory. I downloaded the zip file and you will find three files like: poi-Version-Date.jar; poi-contrib-Version-Date.jar and poi-scratchpad-Version-Date.jar
I downloaded the 2.5.1-final version. I renamed my jars to poi-2.5.1.jar, poi-2.5.1-contrib.jar and poi-2.5.1-scratchpad.jar because my memory cannot hold those complex names for a long time. I installed the library in C:\POI and put them in the Coldfusion Administrator classpath
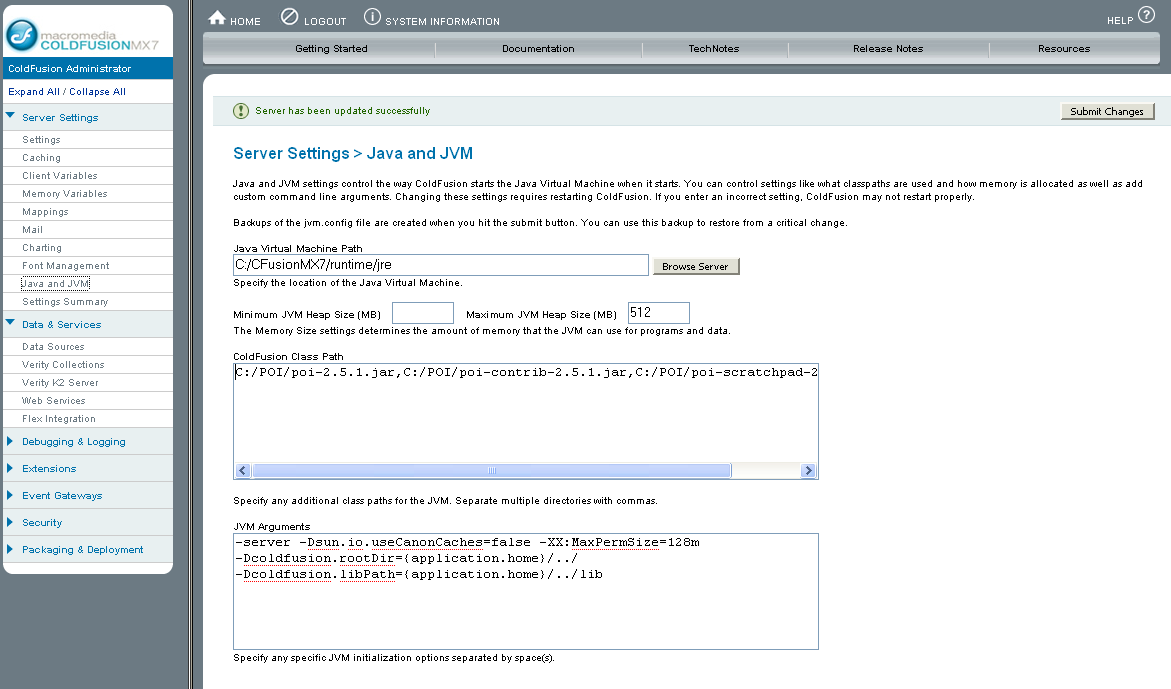
And then I created a test file like the following:
Note: I used a recommendation from Cristial Cantrell http://weblogs.macromedia.com/cantrell/archives/2003/06/using_coldfusio.cfm
<cfscript>
context = getPageContext();
context.setFlushOutput(false);
response = context.getResponse().getResponse();
response.setContentType("application/vnd.ms-excel");
response.setHeader("Content-Disposition","attachment; filename=unknown.xls");
out = response.getOutputStream();
</cfscript>
<cfset wb = createObject("java","org.apache.poi.hssf.usermodel.HSSFWorkbook").init()/>
<cfset format = wb.createDataFormat()/>
<cfset sheet = wb.createSheet("new sheet")/>
<cfset cellStyle = wb.createCellStyle()/>
<!--- Take formats from: http://jakarta.apache.org/poi/apidocs/org/apache/poi/hssf/usermodel/HSSFDataFormat.html --->
<cfset cellStyle.setDataFormat(createObject("java","org.apache.poi.hssf.usermodel.HSSFDataFormat").getBuiltinFormat("0.00"))/>
<cfloop index = "LoopCount" from = "0" to = "100">
<!--- Create a row and put some cells in it. Rows are 0 based. --->
<cfset row = sheet.createRow(javacast("int",LoopCount))/>
<!--- Create a cell and put a value in it --->
<cfset cell = row.createCell(0)/>
<cfset cell.setCellType( 0)/>
<cfset cell.setCellValue(javacast("int",1))/>
<!--- Or do it on one line. --->
<cfset cell2 = row.createCell(1)/>
<cfset cell2.setCellStyle(cellStyle)/>
<cfset cell2.setCellValue(javacast("double","1.223452345342"))/>
<cfset row.createCell(2).setCellValue("This is a string")/>
<cfset row.createCell(3).setCellValue(true)/>
</cfloop>
<cfset wb.write(out)/>
<cfset wb.write(fileOut)/>
<cfset fileOut.close()/>
<cfset out.flush()/>
We have mentioned several times that if you can use SCSI for your VMs, then you should use it. In order to practice what we preach, I downloaded a VHD from the VHD Test Drive program (Windows Server Pro 2003) and hooked it up to a SCSI adapter and booted the machine. It was unpleasantly greeted by the dreaded Blue Screen of Death when booting. As far as the reason why it happens, I really cannot tell. Perhaps it has to do something with the VHD being syspreped and whatnot, but the purpose if this entry is not to tell you why it happens but rather how to get around it.
What I did was that I connected the VM to a virtual IDE controller and booted. I let the sysprep process finish and once I had a Windows Server 2003 logon screen, I turned off the VM. In the configuration screen of Virtual Server, I added a SCSI adapter and then added the VHD to an empty device:
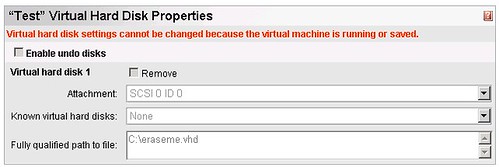
Once this was set, the VM booted without any issues.
Virtual PC 2007 has moved to the Release Candidate stage. You can download it from here.
You can also check out the new features of this release on the Virtual PC Guy's WebLog .
If you had a holiday rush as some of us did maybe you missed some news about Visual Studio Service pack 1 being release.
Scott Guthrie (asp.net, iss, product manager at Microsoft) release today on his blog some really valuable information about this. He points to really good links like
But also more useful information, check it out the whole post:
A few VS 2005 SP1 Links and Information Nuggets
There are many ways to post blogs. You can use the web interface that most blog applications (blogger, community server, wordpress, etc.) offer. This can be very cumbersome and if you hit back by mistake on your browser, then all that you have typed can be gone in a matter of seconds.
I have recently stumbled on some (free) tools that will allow you to blog like a pro. The first one is called Live Writer Beta and is made by Microsoft - I found out about this from Volker's blog today. So far it has been very stable and is very easy to use. It is basically the same thing as using Word. This will get you covered as far as blogging goes, but if you want to add images and such (something our Community Server blog currently does not offer) you will need additional software.
To insert images, get the Flickr4Writer plugin, which will allow you insert images on your blog that are linked from Flickr account:
I am currently uploading my images to flickr using this (OS X) widget, I am pretty sure there is something similar for Vista if you look around (drop me a line if you find one).
Happy Blogging!
Over at IBM developerworks there is an overview of virtualization technologies, starting with the history of virtualization, virtualization methods, and some more information on the current status of virtualization in the IT industry. The article focuses on Linux Virtualization solutions, but the information it contains and the background it gives is worth a read.
Link: Virtual Linux.
Microsoft has recently posted on their website a
plethora of webcasts dealing with many current topics. Of particular interest are the ones posted on Virtualization. The ones that deal specifically with topic follows:
How to Virtualize Infrastructure Workloads
http://www.microsoft.com/emea/itsshowtime/sessionh.aspx?videoid=348Using Application Virtualization to Decrease Your Application Management TCO
http://www.microsoft.com/emea/itsshowtime/sessionh.aspx?videoid=361An Overview of Microsoft's Vision for Virtualization
http://www.microsoft.com/emea/itsshowtime/sessionh.aspx?videoid=337Transitioning to Windows Server Virtualization
http://www.microsoft.com/emea/itsshowtime/sessionh.aspx?videoid=343I have yet to watch them, but if I find something particularly interesting, I will post it on my blog ASAP.
Just want to say happy new year and succes to all the people at ArtinSoft and especially to our blogs readers, this year we have a lot of new things coming, just no migration stuff, but new tools and products that hopefully everybody will love, especially people in the web development world. At this point can't tell more about it...
In the other hand I'll be sharing more knowledge and tips about Asp.net and migrations from ASP to ASP.NET and of course .NET related information.
Stay Tune !
A quick post to wish you all a happy new year!
This is going to be an interesting year, with the release of Windows Vista, possibly Longhorn Server, and all the virtualization products on the pipeline from both Microsoft and the competition. I also think that this year 64-bit usage will increase significantly on the home and workstation front, given the release of Vista 64-bit and the fact that drivers are starting to show up.
So, best wishes to you all, and hope you have a great 2007!!
If you are migrating a Powerbuilder Application to .NET the
more recommend language you can use is VB.NET. This because this language has a
lot of common elements with PowerScript. Lets see some simple comparisons.
Variable definition
A variable is defined writing the Data Type just before the name.
For example:
Integer amount
String name
In VB.NET this will
be
Dim amount as Integer
Dim name as String
Constants
constant integer MAX = 100
In VB.NET this will
be
Const MAX As Integer = 100
Control Flow: If Statement
If monto_cuota=13 Then
nombre= 'Ramiro'
ElseIf monto_cuota=15 Then
nombre= 'Roberto'
Else
nombre= 'Francisco'
End If
This code is almost exactly the same in VB.NET
If
monto_cuota = 13 Then
nombre = "Ramiro"
ElseIf
monto_cuota = 15 Then
nombre = "Roberto"
Else
nombre = "Francisco"
End If
Control Flow: Choose Statement
Choose case monto_cuota
Case Is< 13: nombre='Ramiro'
Case 16 To 48:nombre= 'Roberto'
Else
nombre='Francisco'
End Choose
This code is slightly different:
Dim
monto_cuota As Integer
Dim
nombre As String
Select Case monto_cuota
Case Is < 13
nombre = "Ramiro"
Case
16 To 48
nombre = "Roberto"
Case
Else
nombre = "Francisco"
End Select
Control Flow: For statement
For n = 5 to 25 step 5
a = a+10
Next
In VB.NET
Dim n, a As
Integer
For n = 5
To 25 Step 5
a = a + 10
Next
Control Flow: Do Until, Do While
integer
A = 1, B = 1
//Make
a beep until variable is greater than 15 variable
DO
UNTIL A > 15
Beep(A)
A = (A + 1) * B
LOOP
integer
A = 1, B = 1
//Makes
a beep while variable is less that 15
DO
WHILE A <= 15
Beep(A)
A = (A + 1) * B
LOOP
In VB.NET
Dim A As Integer = 1, B As Integer = 1
'Make a beep
until variable is greater than 15 variable
Do Until a > 15
Beep(a)
a = (a + 1) * B
Loop
'Makes a beep
while variable is less that 15
Do While A <= 15
Beep(a)
a = (a + 1) * B
Loop
This is the migration of a snippet of ASP classic to ASP.Net
Checking that a File Exists ASP Classic
<%
Dim strExists
Dim strNotExists
Dim objFileSystemObjectVar
``
strExists = "exists.txt"
strNotExists = "error.txt"
Set objFileSystemObjectVar = Server.CreateObject("Scripting.FileSystemObject")
' The FileExists method expects a fully qualified path and
' use Server.MapPath
%>
<p>
"<%= strExists %>" exists:
<b><%=objFileSystemObjectVar.FileExists(Server.MapPath(strExists)) %></b>
</p>
<p>
"<%= strNotExists %>" exists:
<b><%= objFileSystemObjectVar.FileExists(Server.MapPath(strNotExists)) %></b>
</p>
Checking that a file exists ASP.NET
<%@ Page Language="VB" %>
<%@ Import Namespace="System.IO" %>
<script language="VB" runat="server">
Dim strExists As String = "exists.txt"
Dim strNotExists As String = "error.txt"
</script>
<p>
"<%= strExists %>" exists:
<b><%=File.Exists(Server.MapPath(strExists))%></b>
</p>
<p>
"<%= strNotExists %>" exists:
<b><%= File.Exists(Server.MapPath(strNotExists))%></b>
</p>
These project extends the VB and C# languages with query,
set and transforms operations. It adds a native syntax for those operations.
The idea of the LINQ project is to make data manipulation
part of the language constructs. Lets see these VB examples for LINQ:
The following examples
associates the Customer class to the Customer table. Just adding the Column Tag
before a field, maps it to a table column.
<Table(Name:="Customers")>
_
Public Class Customer
<Column(Id:=True)>
_
Public
CustomerID As String
…
<Column()> _
Public City As String
…
End Class
To
access the database you do something like:
'
DataContext takes a connection string
Dim db As
DataContext = _
New
DataContext("c:\...\northwnd.mdf")
'Get a typed table to
run queries
Dim Customers As
Table(Of Customer) = db.GetTable(Of Customer)()
'Query for customers from London
Dim q = _
From
c In Customers _
Where
c.City = "London" _
Select c
For Each cust In q
Console.WriteLine("id=" & Customer.CustomerID
& _
",
City=" & Customer.City)
Next
You just create a
DataContext and create typed object that will relate dot the relational tables.
I think this is awesome!!
It is even nicer if you
create a strongly typed DataContext
Partial Public Class Northwind
Inherits DataContext
Public
Customers As Table(Of
Customer)
Public
Orders as Table(Of
Order)
Public Sub New(connection As String)
MyBase.New(connection)
Your
code gets cleaner like the following:
Dim db As New
Northwind("c:\...\northwnd.mdf")
Dim q = _
From c In db.Customers _
Where
c.City = "London" _
Select
c
For Each cust In q
Console.WriteLine("id=" & Customer.CustomerID
& _
",
City=" & Customer.City)
Next
These project will start a
lot of exciting posibilities. I recommed you have a look at’: http://msdn.microsoft.com/data/ref/linq/
This is an old topic but I always like to give some thoughts
on this idea. I really think that in the
future everything will run from the internet. Internet is becoming another
basic need just as electricity, water, gas and telephone. The appearance of new
technologies makes it easy to have Internet even in remote places like beaches
and mountains.
Rich Clients have been defended because it was said that not
a lot of interactivity could be produced by thin clients. It has also been said
that powerful interfaces (with complex gadgets, etc) could be produced in a web
interface. I think that Flash, and AJAX
have shown that despite all believes it is possible. There are still more technologies
that will come. But the easier deployment and the fact that you can use your
web applications everywhere even from a cell phone in a taxi cub.
I also love phases like “If you ask an engineer the time,
he'll tell you how to build a clock.”. Web interfaces are simple and easy to
learn look at blogs like Jon Galloway http://weblogs.asp.net/jgalloway/archive/2003/09/27/29446.aspx
and Microsoft's Inductive User Interface (IUI) initiative it seams like more
people is starting to think in this way.
This post is the second part on the comparison between Virtual Server 2005 R2 SP1 and Windows Virtualization:
- Cluster Support: Both Virtual Server and Windows Virtualization have support for Windows Server clustering
- Scripting support: Both Virtual Server and Windows Virtualization have support for scripting, but Virtual Server uses a COM API and Windows Virtualization a WMI-based API
- Supported VMs: Virtual Server, with SP1, support up to 128 VMs on a single server. Windows virtualization supports as many as the hardware allows.
- Management Interface: Virtual Server has web-based administration tools. Windows Virtualization, on the other hand, will be managed through a MMC snap-in, to put it in line with all other Microsoft’s management solutions.
You can check out the first part here.
Migrating ASP to ASP.NET
Surpinsingly for me. I found that some friends were working on migrating an ASP classic site to ASP.NET. I was impressed to see that there are still sites in ASP classic at ALL!!!!
ASP.NET 2.0 provides so much improvements, you cannot even debug in ASP. ASP.NET 2.0 has better performance and easier to deploy. There is even Intellisense! These days is hard for me not assuming that all IDEs provide the developer aids like that.
Also migrating simple ASP classic code to ASP.NET is not that hard.
Let’s see a simple ASP classic page like:
<%
Dim objConn
Dim objRS
Set objConn = Server.CreateObject(“ADODB.Connection”)
Set objRS = Server.CreateObject(“ADODB.Recordset”)
objConn.ConnectionString = “DRIVER=(SQL Server);server=…”
objConn.Open()
objRS.Open “SELECT * from Items”, objConn
Do While Not objRS.EOF
Response.Write CStr(objRS(“ID”)) + “ – “ + objRS(“Description”) + “<br>”
objRS.MoveNext
Loop
objConn.Close
%>
Migrates easily to:
<%@ Page aspcompat=true Language=”VB” AutoEventWireUp=”false” CodeFile=”Default.aspx.vb” >
<%
Dim objConn
Dim objRS
Set objConn = Server.CreateObject(“ADODB.Connection”)
Set objRS = Server.CreateObject(“ADODB.Recordset”)
objConn.ConnectionString = “DRIVER=(SQL Server);server=…”
objConn.Open()
objRS.Open (“SELECT * from Items”, objConn)
Do While Not objRS.EOF
Response.Write (CStr(objRS(“ID”).Value) + “ – “ + objRS(“Description”).Value + “<br>”)
objRS.MoveNext
Loop
objConn.Close
%>
These are the task to do:
- Remove SET
- Any method in ASP.NET requires its parameters to go inside parenthesis
- ASP.NET does not have default properties so elements as objRS(“ID”) must be changed to objRS(“ID”).Value and objRS(“Description”) to objRS(“Description”).Value
- you must add the aspcompat=true property to the page because of the apartment threading issues
- You should change statements like Dim objRS to Dim objRS as Object it is not an error but it will help you make your code more clear.
You can also download the Migration Assitant from ASP to ASP.NET from:
http://www.asp.net/DownloadWizard.aspx?WizardTarget=AspToAspNetMigrationAssistant
Several times I've been asked something along the lines of “why should I install virtual machine additions on a virtual machine? The virtual machine works fine without them, doesn't it?". I thought it is worth it to quickly mention the benefits of virtual machine additions in this post.
The Virtual Machine Additions included with Virtual Server perform several tasks. They allow better communication between Virtual Server and the guest OS, on things such as time synchronization or the ability to shut down the machine on command. But the most important task performed by the Additions is that they patch the operating system so it can work with what is called Ring Compression.
Operating systems normally run on Ring 0 on x86 CPUs. Ring Compression allows the virtual machine OS to run on Ring 1 on the hardware, allowing the host operating system and the virtual machine monitor to run on Ring 0. By using ring compression, the VMM is able to trap instrucions from the virtual machine that otherwise it is unable to catch – such as memory requests. The alternative, at least in Virtual PC (I’m not 100% possitive Virtual Server follows the same approach) is to run the operating system instructions not on the hardware, but on a binary translator. This is the one of the reasons why after installing the additions you see such an increase in the virtual machine’s performance.
Of course, ring compression is not necessary if you have a CPU with AMD-V or Intel VT technology. In those CPUs, the virtual machine monitor runs on a Ring -1, so guest operating system will run on Ring 0 without any complications.
You can read more about this topic here or here.