Have you ever wished to modify the way Visual Studio imported a COM Class. Well finally you can.
The Managed, Native, and COM Interop Team (wow what a name). It looks like the name of that goverment office in the Ironman movie.
Well this fine group of men, have release the source code of the TLBIMP tool. I'm more that happy for this.
I can know finally get why are some things imported the way they are.
http://www.codeplex.com/clrinterop
You can dowload also the P/Invoke assistant. This assistant has a library of signatures so you can invoke any Windows API.
The WebBrowser control for .NET is just a wrapper for the IE ActiveX control. However this wrapper does not expose all the events that the IE ActiveX control exposes.
For example the ActiveX control has a NewWindow2 that you can use to intercept when a new window is gonna be created and you can even use the ppDisp variable to give a pointer to an IE ActiveX instance where you want the new window to be displayed.
So, our solution was to extend the WebBrowser control to make some of those events public.
In general the solution is the following:
- Create a new Class for your Event that extend any of the basic EventArgs classes.
- Add constructors and property accessor to the class
- Look at the IE Activex info and add the DWebBrowserEvents2 and IWebBrowser2 COM interfaces. We need them to make our hooks.
- Create a WebBrowserExtendedEvents extending System.Runtime.InteropServices.StandardOleMarshalObject and DWebBrowserEvents2. We need this class to intercept the ActiveX events. Add methos for all the events that you want to intercept.
- Extend the WebBrowser control overriding the CreateSink and DetachSink methods, here is where the WebBrowserExtendedEvents class is used to make the conneciton.
- Add EventHandler for all the events.
And thats all.Here is the code. Just add it to a file like ExtendedWebBrowser.cs
using System;
using System.Windows.Forms;
using System.ComponentModel;
using System.Runtime.InteropServices;
//First define a new EventArgs class to contain the newly exposed data
public class NewWindow2EventArgs : CancelEventArgs
{
object ppDisp;
public object PPDisp
{
get { return ppDisp; }
set { ppDisp = value; }
}
public NewWindow2EventArgs(ref object ppDisp, ref bool cancel)
: base()
{
this.ppDisp = ppDisp;
this.Cancel = cancel;
}
}
public class DocumentCompleteEventArgs : EventArgs
{
private object ppDisp;
private object url;
public object PPDisp
{
get { return ppDisp; }
set { ppDisp = value; }
}
public object Url
{
get { return url; }
set { url = value; }
}
public DocumentCompleteEventArgs(object ppDisp,object url)
{
this.ppDisp = ppDisp;
this.url = url;
}
}
public class CommandStateChangeEventArgs : EventArgs
{
private long command;
private bool enable;
public CommandStateChangeEventArgs(long command, ref bool enable)
{
this.command = command;
this.enable = enable;
}
public long Command
{
get { return command; }
set { command = value; }
}
public bool Enable
{
get { return enable; }
set { enable = value; }
}
}
//Extend the WebBrowser control
public class ExtendedWebBrowser : WebBrowser
{
AxHost.ConnectionPointCookie cookie;
WebBrowserExtendedEvents events;
//This method will be called to give you a chance to create your own event sink
protected override void CreateSink()
{
//MAKE SURE TO CALL THE BASE or the normal events won't fire
base.CreateSink();
events = new WebBrowserExtendedEvents(this);
cookie = new AxHost.ConnectionPointCookie(this.ActiveXInstance, events, typeof(DWebBrowserEvents2));
}
public object Application
{
get
{
IWebBrowser2 axWebBrowser = this.ActiveXInstance as IWebBrowser2;
if (axWebBrowser != null)
{
return axWebBrowser.Application;
}
else
return null;
}
}
protected override void DetachSink()
{
if (null != cookie)
{
cookie.Disconnect();
cookie = null;
}
base.DetachSink();
}
//This new event will fire for the NewWindow2
public event EventHandler<NewWindow2EventArgs> NewWindow2;
protected void OnNewWindow2(ref object ppDisp, ref bool cancel)
{
EventHandler<NewWindow2EventArgs> h = NewWindow2;
NewWindow2EventArgs args = new NewWindow2EventArgs(ref ppDisp, ref cancel);
if (null != h)
{
h(this, args);
}
//Pass the cancellation chosen back out to the events
//Pass the ppDisp chosen back out to the events
cancel = args.Cancel;
ppDisp = args.PPDisp;
}
//This new event will fire for the DocumentComplete
public event EventHandler<DocumentCompleteEventArgs> DocumentComplete;
protected void OnDocumentComplete(object ppDisp, object url)
{
EventHandler<DocumentCompleteEventArgs> h = DocumentComplete;
DocumentCompleteEventArgs args = new DocumentCompleteEventArgs( ppDisp, url);
if (null != h)
{
h(this, args);
}
//Pass the ppDisp chosen back out to the events
ppDisp = args.PPDisp;
//I think url is readonly
}
//This new event will fire for the DocumentComplete
public event EventHandler<CommandStateChangeEventArgs> CommandStateChange;
protected void OnCommandStateChange(long command, ref bool enable)
{
EventHandler<CommandStateChangeEventArgs> h = CommandStateChange;
CommandStateChangeEventArgs args = new CommandStateChangeEventArgs(command, ref enable);
if (null != h)
{
h(this, args);
}
}
//This class will capture events from the WebBrowser
public class WebBrowserExtendedEvents : System.Runtime.InteropServices.StandardOleMarshalObject, DWebBrowserEvents2
{
ExtendedWebBrowser _Browser;
public WebBrowserExtendedEvents(ExtendedWebBrowser browser)
{ _Browser = browser; }
//Implement whichever events you wish
public void NewWindow2(ref object pDisp, ref bool cancel)
{
_Browser.OnNewWindow2(ref pDisp, ref cancel);
}
//Implement whichever events you wish
public void DocumentComplete(object pDisp,ref object url)
{
_Browser.OnDocumentComplete( pDisp, url);
}
//Implement whichever events you wish
public void CommandStateChange(long command, bool enable)
{
_Browser.OnCommandStateChange( command, ref enable);
}
}
[ComImport, Guid("34A715A0-6587-11D0-924A-0020AFC7AC4D"), InterfaceType(ComInterfaceType.InterfaceIsIDispatch), TypeLibType(TypeLibTypeFlags.FHidden)]
public interface DWebBrowserEvents2
{
[DispId(0x69)]
void CommandStateChange([In] long command, [In] bool enable);
[DispId(0x103)]
void DocumentComplete([In, MarshalAs(UnmanagedType.IDispatch)] object pDisp, [In] ref object URL);
[DispId(0xfb)]
void NewWindow2([In, Out, MarshalAs(UnmanagedType.IDispatch)] ref object pDisp, [In, Out] ref bool cancel);
}
[ComImport, Guid("D30C1661-CDAF-11d0-8A3E-00C04FC9E26E"), TypeLibType(TypeLibTypeFlags.FOleAutomation | TypeLibTypeFlags.FDual | TypeLibTypeFlags.FHidden)]
public interface IWebBrowser2
{
[DispId(100)]
void GoBack();
[DispId(0x65)]
void GoForward();
[DispId(0x66)]
void GoHome();
[DispId(0x67)]
void GoSearch();
[DispId(0x68)]
void Navigate([In] string Url, [In] ref object flags, [In] ref object targetFrameName, [In] ref object postData, [In] ref object headers);
[DispId(-550)]
void Refresh();
[DispId(0x69)]
void Refresh2([In] ref object level);
[DispId(0x6a)]
void Stop();
[DispId(200)]
object Application { [return: MarshalAs(UnmanagedType.IDispatch)] get; }
[DispId(0xc9)]
object Parent { [return: MarshalAs(UnmanagedType.IDispatch)] get; }
[DispId(0xca)]
object Container { [return: MarshalAs(UnmanagedType.IDispatch)] get; }
[DispId(0xcb)]
object Document { [return: MarshalAs(UnmanagedType.IDispatch)] get; }
[DispId(0xcc)]
bool TopLevelContainer { get; }
[DispId(0xcd)]
string Type { get; }
[DispId(0xce)]
int Left { get; set; }
[DispId(0xcf)]
int Top { get; set; }
[DispId(0xd0)]
int Width { get; set; }
[DispId(0xd1)]
int Height { get; set; }
[DispId(210)]
string LocationName { get; }
[DispId(0xd3)]
string LocationURL { get; }
[DispId(0xd4)]
bool Busy { get; }
[DispId(300)]
void Quit();
[DispId(0x12d)]
void ClientToWindow(out int pcx, out int pcy);
[DispId(0x12e)]
void PutProperty([In] string property, [In] object vtValue);
[DispId(0x12f)]
object GetProperty([In] string property);
[DispId(0)]
string Name { get; }
[DispId(-515)]
int HWND { get; }
[DispId(400)]
string FullName { get; }
[DispId(0x191)]
string Path { get; }
[DispId(0x192)]
bool Visible { get; set; }
[DispId(0x193)]
bool StatusBar { get; set; }
[DispId(0x194)]
string StatusText { get; set; }
[DispId(0x195)]
int ToolBar { get; set; }
[DispId(0x196)]
bool MenuBar { get; set; }
[DispId(0x197)]
bool FullScreen { get; set; }
[DispId(500)]
void Navigate2([In] ref object URL, [In] ref object flags, [In] ref object targetFrameName, [In] ref object postData, [In] ref object headers);
[DispId(0x1f7)]
void ShowBrowserBar([In] ref object pvaClsid, [In] ref object pvarShow, [In] ref object pvarSize);
[DispId(-525)]
WebBrowserReadyState ReadyState { get; }
[DispId(550)]
bool Offline { get; set; }
[DispId(0x227)]
bool Silent { get; set; }
[DispId(0x228)]
bool RegisterAsBrowser { get; set; }
[DispId(0x229)]
bool RegisterAsDropTarget { get; set; }
[DispId(0x22a)]
bool TheaterMode { get; set; }
[DispId(0x22b)]
bool AddressBar { get; set; }
[DispId(0x22c)]
bool Resizable { get; set; }
}
}
ArtinSoft’s top seller product, the Visual Basic Upgrade Companion is daily improved by the Product Department to satisfy the requirements of the currently executed migration projects . The project driven research methodology allows our company to deliver custom solutions to our customers needs, and more importantly, to enhance our products capabilities with all the research done for this purposes.
Our company’s largest customer engaged our consulting department requesting for a customization over the VBUC to generate specific naming patterns in the resulting source code. To be more specific, the resulting source code must comply with some specific naming code standards plus a mappings customization for a 3rd party control (FarPoint’s FPSpread).
This request pushed ArtinSoft to re-architect the VBUC's renaming engine, which was capable at the moment, to rename user declarations in some scenarios (.NET reserved keywords, collisions and more).
The re-architecture consisted in a centralization of the renaming rules into a single-layered engine. Those rules was extracted from the Companion’s parser and mapping files and relocated into a renaming declaration library. The most important change is that the renaming engine now evaluates every declaration instead of only the conflictive ones. This enhanced renaming mechanism generates a new name for each conflictive declaration and returns the unchanged declaration otherwise.
The renaming engine can literally “filter” all the declarations and fix possible renaming issues. But the story is not finished here; thanks to our company’s proprietary language technology (Kablok) the renaming engine is completely extensible.
Jafet Welsh, from the product development department, is a member of the team who implemented the new renaming engine and the extensibility library, and he explained some details about this technology:
“…The extensibility library seamlessly integrates new rules (written in Kablok) into the renaming engine… we described a series of rules for classes, variables, properties and other user declarations to satisfy our customer's code standards using the renaming engine extensibility library… and we plan to add support for a rules-describing mechanism to allow the users to write renaming rules on their own…”
ArtinSoft incorporated the renaming engine for the VBUC version 2.1 and for version 2.2 the extensibility library will be completed.
In our previous post on parallel programming we mentioned some pointers to models on nested data parallelism (NDP) as offered in Intel’s Ct and Haskell derivatives in the form of a parallel list or array (Post).
We want to complement our set of references by mentioning just another quite interesting project by Microsoft, namely, the Parallel Language Integrated Query, PLINQ (J. Duffy) developed as an extension of LINQ. PLINQ is a component of FX. We base this post on the indicated reference.
We find this development particularly interesting given the potentially thin relation with pattern-matching (PM) that we might be exploiting in some particular schemas, as we suggested in our post; hence, it will be interesting to take that possibility into consideration for such a purpose. That would be the case if we eventually aim at PM based code on (massive) data sources (i.e. by means of rule-based programs).
As you might know LINQ offers uniformed and natural access to (CLR supported) heterogeneous data sources by means of an IEnumerable<T> interface that abstracts the result of the query. Query results are (lazily) consumable by means of iteration as in a foreach(T t in q) statement or directly by forcing it into other data forms. A set of query operators -main of them with a nice syntax support via extensions methods- are offered (from, where, join, etc) that can be considered phases on gathering and further filtering, joining, etc, input data sources.
For PLINQ, as we can notice, the path followed is essentially via a special data structure represented by the type IParallelEnumerable<T> (that extends IEnumerable<T>). For instance, in the following snippet model given by the author:
IEnumerable<T> data = ...;
var q = data.AsParallel().Where(x => p(x)).Orderby(x => k(x)).Select(x => f(x));
foreach (var e in q) a(e);
A call to extension method AsParallel is apparently the main requirement from the programmer point of view. But, in addition, three models of parallelism are available to in order to process query results: Pipelined, stop-and-go and inverted enumeration. Pipelined synchronizes query dedicated threads to (incrementally) feed the separated enumeration thread. This is normally the default behavior, for instance under the processing schema:
foreach (var e in q) {
a(e);
}
Stop-and-go joins enumeration so that it waits until query threads are done. In some cases this is chosen, when the query is completely forced.
Inverted enumeration uses a lambda expression provided by the user which to be applied to each element of the query. That avoids any synchronization issue but requires using the special PLINQ ForAll extension method not (yet?) covered by the sugared syntax. As indicated by the author, in the following form:
var q = ... some query ...;
q.ForAll(e => a(e));
As in other cases, however, side-effects must be avoided under this model, but this is just programmer responsibility.
If you have some .NET code that you want to share with VB6, COM has always been a nice option. You just add couple of ComVisible tags and that's all.
But...
Collections can be a little tricky.
This is a simple example of how to expose your Collections To VB6.
Here I create an ArrayList descendant that you can use to expose your collections.
Just create a new C# class library project and add the code below.
Remember to check the Register for ComInterop setting.
using System;
using System.Collections.Generic;
using System.Text;
using System.Runtime.InteropServices;
namespace CollectionsInterop
{
[Guid("0490E147-F2D2-4909-A4B8-3533D2F264D0")]
[ComVisible(true)]
public interface IMyCollectionInterface
{
int Add(object value);
void Clear();
bool Contains(object value);
int IndexOf(object value);
void Insert(int index, object value);
void Remove(object value);
void RemoveAt(int index);
[DispId(-4)]
System.Collections.IEnumerator GetEnumerator();
[DispId(0)]
[System.Runtime.CompilerServices.IndexerName("_Default")]
object this[int index]
{
get;
}
}
[ComVisible(true)]
[ClassInterface(ClassInterfaceType.None)]
[ComDefaultInterface(typeof(IMyCollectionInterface))]
[ProgId("CollectionsInterop.VB6InteropArrayList")]
public class VB6InteropArrayList : System.Collections.ArrayList, IMyCollectionInterface
{
#region IMyCollectionInterface Members
// COM friendly strong typed GetEnumerator
[DispId(-4)]
public System.Collections.IEnumerator GetEnumerator()
{
return base.GetEnumerator();
}
#endregion
}
/// <summary>
/// Simple object for example
/// </summary>
[ComVisible(true)]
[ClassInterface(ClassInterfaceType.AutoDual)]
[ProgId("CollectionsInterop.MyObject")]
public class MyObject
{
String value1 = "nulo";
public String Value1
{
get { return value1; }
set { value1 = value; }
}
String value2 = "nulo";
public String Value2
{
get { return value2; }
set { value2 = value; }
}
}
}
To test this code you can use this VB6 code. Remember to add a reference to this class library.
Private Sub Form_Load()
Dim simpleCollection As New CollectionsInterop.VB6InteropArrayList
Dim value As New CollectionsInterop.MyObject
value.Value1 = "Mi valor1"
value.Value2 = "Autre valeur"
simpleCollection.Add value
For Each c In simpleCollection
MsgBox value.Value1
Next
End Sub
Parallel programming has always been an interesting and recognized as a challenging area; it is again quite full of life due to the proliferation nowadays of parallel architectures available at the "regular" PC level such as multi-core processors, SIMD architectures as well as co-processors like stream processors as we have in (Graphical Processors Units (GPUs).
A key question derived from such a trend is naturally how parallel processors development would be influencing programming paradigms, languages and patterns in the near future. How programming languages should allow regular programmers to take real advantage of parallelism without adding another huge dimension of complexity to the already intricate software development process, without penalizing performance of software engineering tasks or application performance, portability and scalability.
Highly motivated by these questions, we want to present a modest overview in this post using our understanding of some interesting references and personal points of view.
General Notions
Some months ago someone working in Intel Costa Rica asked me about multi-core and programming languages during an informal interview, actually as a kind of test, which I probably did not pass, I am afraid to say. However, the question remains actually very interesting (and is surprisingly related to some of our previous posts on ADTs and program understanding via functional programming, FP). So, I want to try to give myself another chance and try to cover some part of the question in a humble fashion. More exactly, I just want to remind some nice well-known programming notions that are behind the way the matter has been attacked by industry initiatives.
For such a purpose, I have found a couple of interesting sources to build upon as well as recent events that exactly address the mentioned issue and serve us as a motivation. First, precisely Intel had announced last year the Ct programming model (Ghuloum et al) and we also have a report on the BSGP programming language developed by people of Microsoft Research (Hou et al) We refer to the sources for gathering more specific details about both developments. We do not claim these are the only ones, of course; we just use them as interesting examples.
Ct is actually an API over C/C++ (its name stands for C/C++ throughput) for portability and backward compatibility; it is intended for being used in multi-core and Tera-scale Intel architectures but practicable on more specific ones like GPUs, at least as a principle. On the other side BSGP (based on the BSP model of Valiant) addresses GPU programming mainly. The language has its own primitives (spawn, barrier, among the most important) but again looks like C at the usual language level. Thus, the surface does not reveal any pointer to FP, in appearance.
In the general case, the main concern with respect to parallel programming is clear: how can we program using a parallel language without compromising/constraining/deforming the algorithmic expression due to a particular architecture, at least not too much. What kind of uniform programming high-level concepts can be used that behave scalable, portable and even predictable in different parallel architectures? In a way that program structure can be derived, understood and maintained without enormous efforts and costs. In a way the compiler is still able to efficiently map them to the specific target, as much as possible.
Naturally, we already have general programming notions like threads, so parallel/concurrent programming usually get expressed using such concepts strongly supported by the multi-core architectures. Likewise, SIMD offers data-parallelism without demanding particular mind from the programmer. But data "locality" is in this case necessary in order to become effective. Such a requirement turns out not realistic in (so-called irregular) algorithms using dynamic data structures where data references (aliases and indirections) are quite normal (sparse matrices and trees for instance). Thus memory low-latency might result computationally useless in such circumstances, as well-known.
On the other hand, multithreading requires efficient (intra/inter-core) synchronization and a coherent inter-core memory communication. Process/task decomposition should minimize latency due to synchronization. Beside that data-driven decomposition is in general easier to grasp than task-driven. Thus, such notions of parallelism are still involved with specific low-level programming considerations to get a good sense of balance between multi-core and SPMD models and even MPMD.
Plenty of literature back to the eighties and the nineties already shows several interesting approaches in achieving data parallelism (DP) that take these mentioned issues into consideration, uniformly; thus, it is not surprising that Ct is driven by the notion of nested data parallelism (NDP). We notice that BSPG addresses GPU architectures (stream based) in order to build simpler programming model than, for instance, in CUDA. NDP is not explicitly supported but similar principles can be recognized, as we explain later on.
Interestingly, that NDP seminal works on these subject directly points to the paradigm of functional-programming (FP), specifically prototyped in the Nesl language of Blelloch and corresponding derivations based on Haskell (Nepal, by Chakravarty, Keller et al).
FP brings us, as you might realize, back to our ADTs, so my detour is not too far away from my usual biased stuff as I promised above. As Peyton Jones had predicted, FP will be more popular due to its intrinsic parallel nature. And even though developments like Ct and BSGP are not explicitly expressed as FP models (I am sorry to say), my basic understanding of the corresponding primitives and semantics was actually easier only when I was able to relocate it in its FP-ADT origin. Thus, to get an idea of what an addReduce or a pack of Ct mean, or similarly a reduce(op, x) of BSGP, was simpler by thinking in terms of FP. But this is naturally just me.
Parallelism Requirements and FP combinators
Parallel programs can directly indicate, using primitives or the like, where parallel task take place, where task synchronize. But it would be better that the intentional program structure gets not hidden by low-level parallel constraints. In fact, we have to assure that program control structure remains intentionally sequential (deterministic) because otherwise reasoning and predicting behavior can become hard. For instance, to reason about whether we add more processors (cores) we can guarantee that programs (essentially) performance scale. In addition, debugging is usually easier if programmer thinks sequentially during program development and testing.
Hence, if we want to preserve natural programming structures during coding and not be using special (essentially compiler targeting) statements or similar to specify parallel control, we have to write programs in a way that the compiler can derive parallelism opportunities from program structure. For such a purpose we would need to make use of some sort of regular programming structures, in other words, kind of patterns to formulate algorithms. That is exactly the goal the Ct development pursues.
As FP theory decade ago has shown that a family of so-called combinators does exist for expressing regular and frequent algorithmic solution patterns. Combinators are a kind of building-blocks for more general algorithms; they base on homomorphisms on (abstract) data types. Main members of such family are the map and reduce (aka. fold) combinators. They are part of a theory of lists or the famous Bird-Meertens formalism (BMF), as you might know. Symbolically, map can be defined as follows:
map(f, [x1,...,xn]) = [f(x1),..., f(xn)] (for n>= 0)
Where as usual brackets denote lists and f is an operation being applied to each element in a list collecting the results in a new list preserving the original order (map of an empty list is the empty list). As easy to see, many algorithms iterating over collections by this way can be an instance of map. My favorite example for my former FP students was: "to raise the final notes of every student in class in a 5%". But more serious algorithms of linear algebra are also quite related to the map-pattern, so they are ubiquitous in graphic or simulation applications (pointing to GPUs).
Map is naturally parallel; the n-applications of operation "f" could take place simultaneously in pure FP (no side-effects). Hence, expressing tasks using map allows parallelism. Moreover, map can be assimilated as a for-each iteration block able to run in parallel. List comprehensions in FP are another very natural form to realize map.
Nesl original approach which is followed by Nepal (a Haskell version for supporting NDP) and Ct is to provide a special data type (parallel list or array) that implicitly implements a map. In Nepal such lists are denoted by bracket-colon notation, [: :] and called parallel-arrays. In Ct such a type is provided by the API and is called TVEC. Simply using a data type for communicating parallelism to the compiler is quite simple to follow and does not obscure the proper algorithm structure. In Nepal notation, just as simple example, we would write using parallel array comprehensions something like this:
[: x*x | x <- [: 1, 2, 3 :] :]
This denotes the map of the square function over the parallel list [:1, 2, 3:]. Notice that this is very similar to the corresponding expression using regular lists. However, it is interesting to notice that in contrast to normal lists parallel-arrays are not inductively definable, that would suggest trying to process them sequentially, and that would make no sense. Using flat parallel arrays allows DP. However, and that is the key issue, parallel-arrays (TVECs also) can be nested, in such a case a flattening process takes places internally in order to apply in parallel a parallel function over a nested structure (a parallel-array of parallel-arrays) which is not possible in DP. Standard and illustrating examples of NDP are divide-and-conquer algorithms, like the quicksort (qsort). Using NDP lets the flattening handle recursive calls as parallel calls, too. For instance, as key part of a qsort algorithm we calculate:
[: qsort(x) | x <-[: lessThan, MoreThan :]:]
Assume the lessThan and moreThan are parallel arrays result of the previous splitting phase. In this case the flattening stage will "distribute" (replicate) the recursive calls between data structure. The final result after flattening will be a DP requiring a number of threads that depends on the number of array partitions (O(log(n))) not on the number of qsort-recursive calls (O(n)); which can help to balance the number of required threads at the end independently of the order of the original array. This example shows that NDP can avoid potential degeneration of control (task) based parallelism.
Evidently, not every algorithm is a map-instance; many of them are sequential reductions from a data type into a "simpler" one. For instance, we have the length of a list which reduces (collapses) a list into a number or similarly the sum of all elements of a list. In such a case the threads computing independent results must be synchronized into a combined result. This corresponds to the reduce class of operations. Reduce (associative fold) is symbolically defined as follows:
reduce (e, @, [x1, ..., xn]) = e @x1@...@xn
where "@" denotes here an associative infix operator (function of two arguments).
Reduce can be harder to realize in parallel in comparison to map due its own nature, in general; scans/tree-contraction techniques offer one option providing reduce as a primitive. Bottom-line is that they can be cleanly separated of big previous map-steps. In other words, many algorithms are naturally composed of "map"-phases followed by reduce-phases so particular parallelization and optimization techniques can be employed based on this separation at the compilation level.
We notice that map-steps can be matched with the superstep-notion which is very proper of the BSP model (which lies beneath the BSPG language). On the other hand reduce-phases are comparable with after-barrier code in this language or points where threads must combine their outputs. However, BSGP does not have flattening, as we could observe in the report.
If the implemented algorithm naturally splits into well-defines map (superstep)-reduce (barrier) phases then NDP-thinking promotes better threading performance and more readability of the code intentionality. In addition, many reduce operations can be very efficiently implemented as operations on arrays according to previously calculated indexing parallel arrays (as masks) which are directly supported in Ct (for instance, partition, orReduce, etc.) according to the source. In addition standard scan algorithms are supported in the library, thus scan-based combinations can be used.
In a forthcoming (in a hopefully shorter) second part of this post, we will be briefly discussing some applications of NDP to some pattern-matching schemas.
I am a firm believer in program understanding and in that our computer skills will allow us to develop programs that will understand programs and maybe in the future even write some of them :).
I also belive that natural languages ans programming languages are two things with a lot in common.
These are just some ideas about this subject.
"A language convertion translates one languate to another language, while a language-level upgrade moves an application from an older version of a language to a modern or more standardized version of that same language. In both cases, the goal is to improve portability and understanbility of an application and position that application for subsequent transformation", Legacy Systems, Transformation Strategies by William M. Ulrich.
An natural language convertion is exactly that. Translating one language to another language.
Natural language processing and transformation have a lot in common with automated source code migration. There is a lot of grammar studies on both areas, and a lot of common algorithms.
I keep quoting:
"Comparing artificial language and natural language it is very helpful to our understanding of semantics of programming languages since programming languages are artificial. We can see much similarity between these two kinds of languages:
Both of them must explain "given'" languages.
The goal of research on semantics of programming languages is the same as that of natural language: explanation of the meanings of given language. This is unavoidable for natural language but undesirable for programming language. The latter one has often led to post-design analysis of the semantics of programming languages wherein the syntax and informal meaning of the language is treated as given( such as PL/I, Fortran and C ). Then the research on the semantics is to understand the semantics of the language in another way or to sort out anomalies, ommisions, or defects in the given semantics-which hasn't had much impact on the language design. We have another kind of programming languages that have formal definitions, such as Pascal, Ada, SML. The given semantics allow this kind of programming language to be more robust than the previous ones.
Both of them separate "syntax'" and "semantics'".
Despite these similarities, the difference between the studies of natural and artificial language is profound. First of all, natural language existed for thousands of years, nobody knows who designed the language; but artificial languages are synthesized by logicians and computer scientists to meet some specific design criteria. Thus, `` the most basic characteritic of the distinction is the fact that an artificial language can be fully circumscribed and studied in its entirety.''
We already have developed a mature system for SYNTAX. In 1950's, linguist Chomsky first proposed formal language theory for English, thus came up with Formal Language Theory, Grammar, Regular Grammar, CFG etc. The ``first'' application of this theory was to define syntax for Algol and to build parser for it. The landmarks in the development of formal language theory are: Knuth's parser, and YACC-which is a successful and ``final''application of formal language theory.
"
from Cornell university http://www.cs.cornell.edu/info/projects/nuprl/cs611/fall94notes/cn2/cn2.html
Jing Huang
I also will like to add a reference from an interesting work related to pattern recognition a technique used both in natural language processing (see for example http://prhlt.iti.es/) and reverse engineering.
This work is from Francesca Arcelli and Claudia Raibulet from Italy and they are working with the NASA Automated Software EngineeringResearch Center
http://smallwiki.unibe.ch/woor2006/woor2006paper3/?action=MimeView
In VB6 it was very simple to add scripting capabilities to your application.
Just by using the Microsoft Script Control Library
You can still use this library in .NET just as Roy Osherove' Bloc show in
http://weblogs.asp.net/rosherove/articles/dotnetscripting.aspx
However there are some minor details that must be taken care of:
* Objects must be exposed thru COM (Add the [ComVisible(true)] attribute to the class
* Add the ComVisible(true) attribute to the AssemblyInfo file
* Make these objects public
* Recommended (put your calls to Eval or ExecuteStatement inside try-catch blocks).
And here's an example:
using System;
using System.Windows.Forms;
namespace ScriptingDotNetTest
{ [System.Runtime.InteropServices.ComVisible(true)]
public partial class frmTestVBScript : Form
{ public int MyBackColor
{ get { return System.Drawing.ColorTranslator.ToOle(this.BackColor); } set { this.BackColor = System.Drawing.ColorTranslator.FromOle(value); } }
MSScriptControl.ScriptControl sc = new MSScriptControl.ScriptControl();
private void RunScript(Object eventSender, EventArgs eventArgs)
{ try
{ sc.Language = "VbScript";
sc.Reset();
sc.AddObject("myform", this, true); sc.ExecuteStatement("myform.MyBackColor = vbRed"); }
catch
{ MSScriptControl.IScriptControl iscriptControl = sc as MSScriptControl.IScriptControl;
lblError.Text = "ERROR" + iscriptControl.Error.Description + " | Line of error: " + iscriptControl.Error.Line + " | Code error: " + iscriptControl.Error.Text;
}
}
[STAThread]
static void Main()
{ Application.Run(new frmTestVBScript());
}
}
}
TIP: If you don find the reference in the COM tab, just browse to c:\windows\system32\msscript.ocx
When people decide to migrate their VB6 applications they eventually end up questioning where they should go. Is VB.NET or C# a good choice?
I have my personal preference, but my emphasis is in developing the technology to take where YOU want to go.
VB.NET is a VB dialect very similar to VB6. It supports several constructs and it makes the changes easier.
C# has several differences from VB6, but it has it a growing language with lots of enthusiasts in its community.
Obviously migrating VB6 to VB dialect is a task far more easier than migrating to a different language.
However we are a research company with years of work in this area and challenges is just what we love.
Let's use a methaphor here.
My beautiful wife, was born in Moscow, Russia. Like her, I really enjoy reading a good book. Some of my favorite authors are
russian authors like Dostoievsky, Tolstoi and Chejov. However I still do not speak russian. I have tried, and I will keep trying but
I still don't know russian. I have read only translations of their books, and I really enjoy them.
As a native speaker my wife always tells me, that it is not the same to read those books in another language besides russian.
And they are phrases (specially in Chejov books that I might not completely understand) but I really got the author
message and enjoyed it.
Translating a book from russian to a more similar language like Ucranian is easier than translating it to English or Spanish.
But I think everybody agrees that is a task than can be done.
You can use terrible works case scenarios, but these scenarios must be analized.
Let see (I took these example from the link in that Francesco put in my previous post http://blogs.artinsoft.net/mrojas/archive/2008/08/07/vb-migration-not-for-the-weak-of-mind.aspx)
If you have code like this:
Sub CopyFiles(ByVal throwIfError As Boolean)
If Not throwIfError Then On Error Resume Next
Dim fso As New FileSystemObject
fso.CopyFile "sourcefile1", "destfile1"
fso.CopyFile "sourcefile2", "destfile2"
fso.CopyFile "sourcefile3", "destfile3"
' seven more CopyFile method calls …
End Sub
and you translate it to:
void CopyFiles(bool throwIfError)
{
Scripting.FileSystemObject fso = new Scripting.FileSystemObjectClass();
try
{
fso.CopyFile("sourcefile1", "destfile1", true);
}
catch
{
if (throwIfError)
{
throw;
}
}
try
{
fso.CopyFile("sourcefile1", "destfile1", true);
}
catch
{
if (throwIfError)
{
throw;
}
}
try
{
fso.CopyFile("sourcefile1", "destfile1", true);
}
catch
{
if (throwIfError)
{
throw;
}
}
// seven more try-catch blocks
}
I think that the russian is really keep in this translation.
First of all. When you do a translation, you should try to make it as native as possible. So why will you keep using a COM function when there is an
equivalent in .NET. So why not use System.IO.File.CopyFile("sourcefile1", "destfile1", true); instead?
Second of all. The On Error Resume Next, I agree is a not a natural statement in C#. I really think that using it could provide results that are less predictable.
Why? Becuase after executing it, are you sure that all the CopyFile occurred successfully? I would prefer wrapping the whole code inside a try-catch instead of trying
to provide an implementation that is not natural in C#, will Aspect Oriented programming provide a clean solution for this cases. Maybe?
RPG and COBOL to Object Oriented Programming, PowerBuilder to C#, Hierarquical Databases to Relational Databases are just the kind of challenges we have faced in our research project.
Not everything is easy, and we might not be able to automate all the tasks (commonly due to the cost of implementing the automation not becuase of feasability).
But at the end Could you understand the whole novel?, even if you didn't understand the joke in the one of the paragraphs in the page?
My years of reading make be belive that you can.
Console applications are still very useful for me.
I write like 125 console applications in the morning and like 4 or 5 in the afternoon.
In one of these applications that was running a long process I just started wandering:
what will happen with Lost? Will ABC ever finish this series?
And If someone presses Ctrl-C will I be able to catch it?
And indeed, the greate C# provides a very easi way to do it:
static void Main(string[] args)
{ Console.CancelKeyPress +=
delegate(object sender, ConsoleCancelEventArgs e)
{ Artinsoft.VBUMKernel.Implementations.UpgradeCommand.StopAllUpgradeProcess(true);
Console.WriteLine("Process aborted by user!"); };
//Long running process
}
Motivation:
I hate to be disappointed. Specially if it is by a person you had respect for. And that's exactly what Francisco Balena from VB Migration Partner, has done. I have respected him for his books and all his VB6 experience. In terms of legacy VB6 code he is a monster. He is the man.
But in terms of code migration...
I'm not saying this because I work on code migration or maybe I'm biased a little by the fact that I work almost 10 years with a company that has done source code migration research on a big number of legacy languages such as COBOL, RPG, PL\1, Algol, Progress, PowerBuilder and also VB6.
I can tell the difference between a "compiler" and a system that rewrites a expression to the closest equivalent in the target language. We are aware of limitations. We are aware of paradigm differences and functional equivalence, but we talk from experience. We talk about our results. And we have proven those things we talk about.
Let's says you create a Cobol Library with a "MOVE" function, and a COBOLPicture Type and add minus, divide, and add operators. And I write something like:
CobolPicture x = new CobolPicture("XXXX");
x.move(10);
x.add(10);
We have things like that, and it works. It's feasible and maybe there are cases where that is a solution. But we are also proud of have researchers that have been able to detect pattern to rewrite something like that like:
int x = 0;
x = 10;
x+=10;
And saying, that something is not possible just because you can't or you dont like it, just seem uneducated to me.
All of this has motivated me to start a series of chapters I for a small blog book I will call VB Migration (not for the weak of mind).
For those of you, who really are tecnology savvy and are in the process of a VB Migration, this is YOUR book.
Milan Negovan in his blog aspnetresources recently published an excerpt of Michael Feathers' book Working Effectively with Legacy Code. I liked the excerpt so much and I believe that it is so pertinent to the topic of my blog that I also will reproduce it verbatim.
--
Often people who spend time working on legacy systems wish they could work on green-field systems. It’s fun to build systems from scratch, but frankly, green-field systems have their own set of problems. Over and over again, I’ve seen the following scenario play out:
An existing system becomes murky and hard to change over time. People in the organization get frustrated with how long it takes to make changes in it. They move their best people (and sometimes their trouble-makers!) onto a new team that is charged with the task of “creating the replacement system with a better architecture.”
In the beginning, everything is fine. They know what the problems were with the old architecture, and they spend some time coming up with a new design. In the meantime, the rest of the developers are working on the old system. The system is in service, so they receive requests for bug fixes and occasionally new features.
The business looks soberly at each new feature and decides whether it needs to be in the old system or whether the client can wait for the new system. In many cases, the client can’t wait, so the change goes in both. The green-field team has to do double-duty, trying to replace a system that is constantly changing.
As the months go by it becomes clearer that they are not going to be able to replace the old system, the system you’re maintaining. The pressure increases. They work days, nights, and week-ends. In many cases, the rest of the organization discovers that the work you are doing is critical and that you are tending the investment that everyone will have to reply on in the future.
The grass isn’t really much greener in the green-field development.
--
I concord 100% with Michael Feathers. Rewriting code is something that can be achieved only at a very large rate of consumption of time and money! My thesis is that migration, specially automatic migration, is often the best option. You can easily change the platform and then focus on rewriting/rearchitecting only the pieces that truly deserve it. This has been proven over and over again at ArtinSoft.
As anyone attempts to support
migration,
refactoring or related automated
software transformation tasks, some level of
understanding of programs is required, as we might be expecting. The more complex the transformation is the deeper such an understanding could turn to be. Tools like standard compilers stay at the language level; for instance, to translate an “if” statement into alternate sequences of low-level code, independently of what functionality it represents at the application domain. However some migration related tasks usually demand a deeper understanding, for instance when one has to decide that some path of an “if” has to be abstracted as a method for some special domain specific related reason. Thus, a regular compiler translate from a higher into a lower level of semantics, migration tools might also require the opposite direction, in addition. Hence, a measure of understanding capability (
complexity) is involved when dealing with software manipulation.
Naturally, the same is true for human beings, programmers, in usual maintenance labor or more specifically when beginners learn to program. In this last case, some kind of programming exercises help to determine how much understanding the student possesses about the language, an algorithm and its implementation. We might ask ourselves in such a scenario, how complex an exercise could be, how much effort, knowledge and tasks the exercise might involve: A not so easy question that we want to start to investigate, initially in terms of an
e-learning situation for pragmatic reasons. For such a purpose, we have prepared a technical report explaining in more detail the context and some interesting angles of the problem. We invite the interested reader to take a look at the
report.
In the past, the concept of
business continuity was typically associated with a company's ability to
recover from natural disasters (fires, flooding, earthquakes, hurricanes). The
events of September 11th changed the paradigm, ending the somewhat
lax attitude towards business continuity planning and turning attention to
those threats having an element of human intent. Moreover, business continuity
planning began focusing not only on allowing an organization to continue
functioning after and during a disaster, but on reducing its impact, hence
minimizing the risk of extended disruptions.
Undeniably, the traditional
approach to business continuity requirements has shifted, driven by the demands
of globalization and high-tech society. It has grown out of the response and
recovery focus and into prevention strategies and techniques. Under this new
paradigm business continuity emphasizes on managing mission critical business assets
and processes to ensure continuous availability.
Business continuity planning is a
crucial part of an organization's overall risk management, and in a world where
information is power and technology is a decisive business enabler, every analysis
around contemporary threats with a potential of causing severe damage to the
organizational infrastructure leads to the assessment of operational risk linked
to information systems. This certainly recognizes the value of software
assets in today's business infrastructure, taking into account the fact
that significant investments in intellectual capital have usually been embedded
in the systems over the years, comprising the back-bone of many companies.
Therefore, a modern structured approach to managing uncertainty related to
threats encompasses all the necessary averting to ensure reliability, correct
functioning and scalability of business critical applications.
Modern organizations must secure their
continuity considering the increasing complexity and interconnection brought by
the reliance on technology to accomplish their goals. Those with business
critical applications will certainly realize the grave impact of system
malfunction upon business continuity, and the implications for stakeholders of
damage to the organization naturally deems it as unacceptable. Protecting the
financial health and stability of an organization is an essential issue for
management, and the high impact risk associated with vital software
applications make this area of business continuity planning highly relevant on
many companies.
Risk avoidance or reduction strategies linked to information assurance
have to deal with the applications'
security, performance and other technical capabilities, with development and
maintenance costs and support availability constituting critical issues to
consider. In fact, governmental entities and organizations in the power,
telecommunication, health, banking and financial industries are subject to
regulations that aim to protect public interest, including systemic failure
among its previsions to ensure information confidentiality, integrity,
authentication and availability.
But the concept of business
continuity is not limited to regulated public utility infrastructures only. Of
course, it's fairly obvious how some minutes of downtime can seriously affect a
large financial institution, but losing access to information systems has consequences
on any type of business. Business continuity is vital to business success, and in
today's interrelated world, practically every aspect of a company's operation
is vulnerable to fatal disruption. And the aforementioned value of software
assets applies to any type of organization, making it an objectionable
operational risk to maintain exposed, unsupported critical applications that
may not run properly. And modernizing them through non-disruptive methods like automated software migration
effectively contains the issues.
... in fact, a very common question we hear out there when people begin
considering upgrading from VB to .NET: “should I migrate my Visual Basic 6.0
applications to VB.NET or C#?”
Well, Google on the subject and this seems to be an endless
discussion, but let’s start by saying that Microsoft is entirely compromised
with the future of both languages, and they have done great efforts to ensure
that both VB.NET and C# provide the full-power of the .NET Framework. This was
clearly stated during the last TechEd, where I went to both the “Meet the VB
Team” and “Meet the C# Team” sessions. They talked about the future of both
languages, and made clear that there are no riffs between the teams. They even
have Tuesday dinner nights and work together when looking for common solutions.
In fact there are several people working on both teams. Of course, each team
has invested in different features, but this only result in advantages to
developers, providing a better opportunity to opt for the language that better
fits each particular job.
The truth is both VB.NET and C# are first-class citizens on the Common
Language Runtime (CLR) with equal access to the same framework features. So in
the end the decision should be based on your specific needs, that is, your
available resources and customer demands if we are talking about business
applications. For example, if most of your developers have been working with VB
6.0 they will probably feel more comfortable with VB.NET. On the other hand, if
you have a Java or C++ code base coexisting with your VB applications, it might
be better to migrate your VB6 systems to C#, a language that is more
comfortable for programmers exposed to some other object oriented languages due
to its syntax, constructions and usability. However, the real work on a VB6 to
.NET migration is dealing with the Framework and moving your mental model from
COM to .NET, so the transition is not just about syntax and semantics issues.
By the way, we’ve seen a few people suggesting a double path
approach for those who chose to migrate their VB6 applications to C#. This idea
mostly comes from those who offer a solution that only converts to VB.NET, and
they even say it’s irrational to think about jumping from VB6 to any .NET
language other than VB.NET. Well, the immense set of differences between VB6
and C# or VB.NET are accurately resolved by ArtinSoft’s Visual Basic Upgrade
Companion tool, and about half of our customers can tell those unbelievers better.
You’ll find detailed info about that here.
Every once in a while when trying to install the VBUC you may run into error 2869:
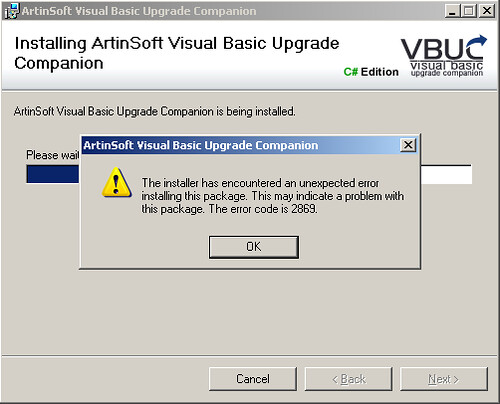
This error, as you can see, doesn't really give you any insight on what may be wrong with the installation. Well, thanks to this blog post, here is a quick process you can follow to troubleshoot the installation and get the actual error that is being masked:
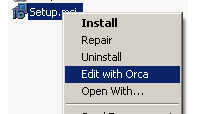
- First, you need to have ORCA installed on your system. ORCA is available as part of the Windows SDK.
- Once you have it installed, find the file setup.msi from the VBUC installer package. Right click on it and select "Edit with ORCA" from the popup menu:
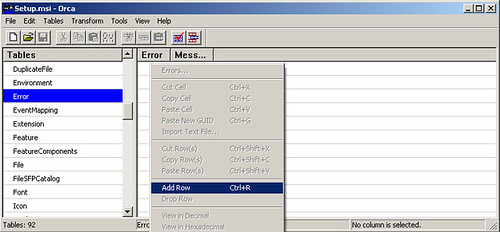
- Once in ORCA, in the Table panel, scroll down and highlight the "Error" line. On the right-hand panel right-click and select Add Row:
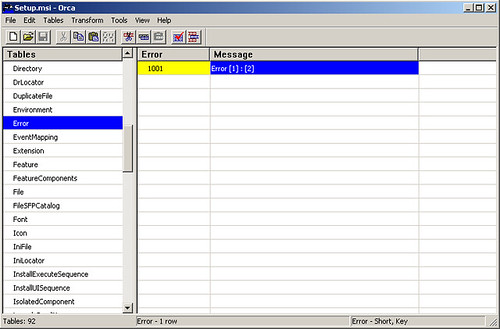
- In the panel that is displayed, enter "1001" for the Error, and "Error [1]:[2]" on the Message. Press OK and the table should look like the following:
- Once you are done editing, save the file in ORCA, close it, and launch the installer. You will now get a more explanatory error:
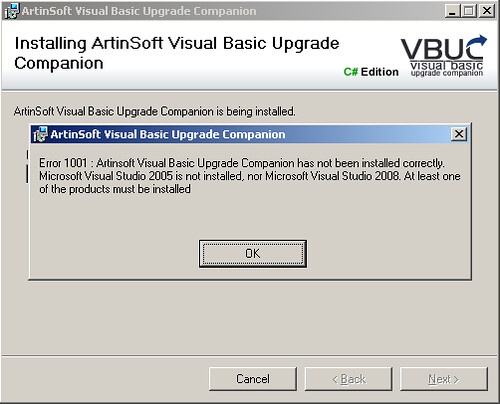
As you can see, in this case at least, the error was caused by not having one of the requirements, Visual Studio (2005 or 2008) installed. This only applies to the current version of the VBUC, as the next version will have these issues with the error messages solved. I still wanted to put this out there, as I got some feedback on it last week.
In our previous post on pattern-matching and ADTs we used Scala for illustrating the idea of pattern extension as a complement to the notion of extractors as defined in Scala (See Post). We want to deepen and discuss some interesting points and derivations related to this requirement that we consider a key one.
By pattern extension we mean the possibility of adding or changing a pattern or combining it with other patterns in different new ways, in other words to have more modularity at this level of the programming or specification language. We know that patterns are available in several (no mainstream) languages however patterns are not usually treated as first-order citizens of such languages. A pattern is usually a sort of notation that the compiler traduces in normal code but not a value in the language. We consider that as an important limitation to the reuse and modularity of application in cases where patterns are numerous as in rule based systems with big amounts of rules. A pattern is actually that important as a query in an information system is, so it is related to a use case and might deserve being handled correspondingly.
Scala provides a nice way to connect patterns with classes as we know. However, Scala does not directly support extensibility at the pattern level as we are figuring out. In this post, we want to illustrate our ideas by developing a simple case using Scala. We want to reify patterns using objects to make the requirement more evident, we exploit many of the facilities that Scala provides but show a limitation we come across as well.
Suppose we want to define our pattern language as an idiom and to have more control over some operational facets of pattern-matching those we might be willing to change or customize. For instance, we would like to code a pattern that matches floating-point values but allows that the pattern matches approximately the muster (with a certain error margin). We want that such functionality would be cleanly a part of a "new" pattern. That is, although things like pattern guards could be used for such a purpose, we want to encapsulate this form of "fuzzy matching" and eventually parameterize it in a class of objects. Notice that for some class of classification problems fuzzy matching can be helpful, hence the example is not completely artificial. Other examples are evidently possible, too. Naturally, if we define our own atomic patterns, we should be able to construct our (boolean) combinations of them, too.
For our purposes, we will define a model of pattern by means of standard OO classes. We assume a very simple protocol (interface) to be satisfied by our family of patterns. We denote this protocol, by the following Scala trait:
trait IPattern[T]{
val value:T
def transduce(e:Any)=e
def matches(e:Any):Option[T] = None
def handle(c:Option[T]) = c
def `:>`(e:Any) = handle(matches(transduce(e)))
}
abstract class AnyPattern extends IPattern[Any]
The matching function is actually located in the method `:>`. The idea is that a pattern is allowed to first transduce the object to match before matching takes place; then the pattern matches the object and finally the "handle" functionality can be added to eventually cope with some particular condition after matching to transducer the result. As seen, we keep the design quite simple according the scope of this post. We assume the transduction does not change the type of neither the object nor the result. Results are given as instances of Scala class Option[T]. The instance field "value" is used by constant patterns those like numbers. We only handle patterns without binding just for simplicity; it can be easily extended for such a purpose.
Now, we can add a wildcard pattern (that matches every object, like _ in Scala)
object TruePattern extends AnyPattern{
val value = null;
override def matches(e:Any):Option[Any] = Some(e)
}
Similarly a class for exact pattern matchin of integers can be defined:
case class IntPattern(val value:Int) extends AnyPattern{
override def matches(e:Any):Option[Int] =
if(value==e) Some(value) else None
}
Let us present our fuzzy pattern for floating point:
case class FloatPattern(val value:Double) extends AnyPattern{
var epsilon:Double=0.01;
private def dmatches(e:Double):Option[Double]={
val diff = Math.abs(value - e );
if(diff<epsilon) return Some(diff)
else return None
}
private def imatches(e:Int):Option[Double]=matches(e.asInstanceOf[Double])
override def matches(a:Any):Option[Double] = a match{
case a:Int => imatches(a)
case a:Double => dmatches(a)
case _ => None
}
}
The pattern accepts integers and values that are at the 0.01 (a default for variable epsilon) distance of the pattern value, a parameter of the pattern. We return as value of the match this difference in absolute value.
As additional examples we define additional pattern combinators (in our algebra of own patterns) for "not", "and" and "or". We show the first two of them, nicely expressible in Scala. Notice that an expression (p `:>` e) produces the matching from pattern p with element e in our notation.
case class NotPattern(val value:AnyPattern) extends AnyPattern{
override def matches(e:Any):Option[Any]= {
val res:Option[Any] = (value `:>` e);
res match {
case Some(_) => return None
case _ => return Some(e)
}
}
}
case class AndPattern(val value:AnyPattern*) extends AnyPattern{
override def matches(e:Any):Option[Any]= {
val res:Option[Any] = Some(e);
for(v <- value){
val res = (v `:>` e);
res match {
case Some(z) => ;
case _ => return None
}
}
return res;
}
}
A guard pattern is also possible too (in this case the value is a Boolean lambda representing the guard):
case class GuardPattern(val value:(Any => Boolean)) extends AnyPattern{
override def matches(e:Any):Option[Unit]={
if(value(e)) return Some()
else return None
}
}
Now, let us add some sugar:
object _Patterns{
def _t = TruePattern;
def _$(x:Int) = IntPattern(x);
def _$(x:Double) = FloatPattern(x);
def _not(x:AnyPattern) = NotPattern(x);
def _and(x:AnyPattern) = AndPattern(x:_*);
def _or(x:AnyPattern*) = OrPattern(x:_*);
def _when(x:Any=>Boolean) = GuardPattern(x);
}
def even(x:Any) = x match{
case x:Int => x%2==0
case _ => false
}
Using this, we might write: _and(_not(_when(even)), _or(_$(1), _$(2)))
to denote a silly pattern that checks for a not even number that is 1 or 2; in other words matches just a 1.
As a final remark, we can be tempted to model these pattern classes adding extractors for representing them as Scala patterns. However, Scala limitations on "objects" (they have to be parameter less) and the "unapply" functions (they are unary) avoid such a possibility. Once again we identify an interesting feature for the language around this limitation.
As a continuation of our previous posts on ADTs, rules and pattern-matching, we go on with our work studying some alternatives to pattern extensibility and generation (see post 1 and post 2). For the extensibility case, we considered delegation by inheritance as an alternative, where we are currently using the programming language Scala for our illustration. In our previous post, we supported the claim the Scala compiler could be able to help in this aspect. In this post we consider pattern generation out from classes, once again, we identify a potential requirement for the programming languages under our study.
In general, we recall our goal is to discover features or their eventual absence in programming languages that give support to an ADT modeling style within a OOP environment. Our motivation and justification comes from the field of automated software transformation (as understood in www.artinsoft.com) and specifically exploring features in languages that properly help to specify transformation rules in a modular and reusable way. The ability to write rules is certainly a central and distinctive element of software transformation tools; especially in the case the feature is available to the final user in order to customize his/her own transformation tasks (as approached for instance in www.aggiorno.com ).
We have already seen how a pattern can be associated with a class in Scala which provides a very natural bridge between rules based programming and OOP. Patterns are views of objects that allow an easy access to its relevant subparts in a particular context, as we know. However, it is programmer’s responsibility to manually build the pattern, in the general case. And knowledge about the set of relevant destructors of the object is required, obviously. And this is usually a matter of domain specific semantics, thus we cope with a task that is difficult to automate.
The notion of destructor is central to ADTs and very particularly when compiling pattern matching. In OOP, destructors are usually implemented as so-called getters (or properties) but, interestingly, neither particular syntax nor semantics in mainstream OOP languages distinguishes them as such from other kind of methods, as we do have for the (class) constructors. In Scala, however, destructors can be automatically generated in some cases which is a fine feature. For instance, consider a simple model for symbolic expressions, defined as follows:
trait ISexp
class Sexp(val car:ISexp, val cdr:ISexp) extends ISexp{
}
class Atom(val value:String) extends ISexp
In this case Scala injects methods for accessing car and cdr fields, thus, in this case destructors are easily recognized. In the case the class would be a case-class the corresponding pattern is indeed generated as indicated by the constructor declaration. But what happens when the class specification is not Scala code or is not given by this explicit way, as in example.
Thus, an interesting question arises if we would want to support semi automated generation of patterns out of classes which are not available in a form that clearly exhibits its destructors.
In ADTs, a destructor is an operator (functor) f that gives access to one parameter of a constructor c. In other words, following invariant should hold in the ADT theory:
Forall x:T: f(c(…, x, ….)) = x
Or if we prefer using an OOP notation:
(new c(…,x,…)).f() = x
In terms of the type system we should have f: () => T where T is the declared type of formal parameter position where x occurs in c.
This provides us with a criterion for guessing candidates for destructors given a class. However, in order to generate code for a pattern, we would need to query the class implementing the ADT looking for such kind of candidates. However, in the case of Scala, we only have reflection as an alternative to perform the required query because there is no code model exposed as class model. Fortunately, the reflection facilities of Java fill the gap. The nice thing is the full interoperability of Scala with Java. The flaw is that we have to generate source code, only.
In order to evaluate the concept, we have developed a very simple Scala prototype that suggests destructors for Java and Scala classes and for generating patterns for such candidates.
For instance, for the classes of the Sexp model given above we automatically get as expected
object Atom {
def unapply(x:sexps.Atom)=Some(x.value)
}
object Sexp {
def unapply(x:sexps.Sexp)=Some(x.car, x.cdr)
}
For a class like java.lang.Integer we get something unexpected:
object Integer {
def unapply(x:java.lang.Integer)=Some(x.intValue, x.toString, x.hashCode)
}
Likewise for the class java.lang.String:
object String {
def unapply(x:java.lang.String)=
Some(x.toCharArray, x.length, x.getBytes, x.hashCode)
}
The overloading of constructors plays at this time an important role on the results. Unfortunately, Scala pattern abstraction does not correctly work if we use overloading for the unapply method. Thus, we have to pack all the possibilities in just one definition. Essential was actually, that we have identified additional requirements which are interesting to get attention as a potential language features.
This is way a discused with a friend for migrating a VB6 RDS CreateRecordset
Private Function Foo(rs As ADOR.Recordset) As Boolean
On Error GoTo Failed
Dim ColumnInfo(0 To 1), c0(0 To 3), c1(0 To 3)
Dim auxVar As RDS.DataControl
Set auxVar = New RDS.DataControl
ColInfo(0) = Array("Value", CInt(201), CInt(1024), True) ColInfo(1) = Array("Name", CInt(129), CInt(255), True)
Set rs = auxVar.CreateRecordSet(ColumnInfo)
Foo = True
Exit Function
Failed:
Foo = False
Exit Function
End Function
According to MSDN the CreateRecordset function takes a Varriant array with definitions for the columns. This definitions are made up of four parts
| Attribute |
Description |
| Name |
Name of the column header. |
| Type |
Integer of the data type. |
| Size |
Integer of the width in characters, regardless of data type. |
| Nullability |
Boolean value. |
| Scale (Optional) |
This optional attribute defines the scale for numeric fields. If this value is not specified, numeric values will be truncated to a scale of three. Precision is not affected, but the number of digits following the decimal point will be truncated to three. |
So if we are going to migrate to System.Data.DataColumn we will used a type translation like the following (for now I’m just putting some simple cases)
| Length |
Constant |
Number |
DataColumn Type |
| Fixed |
adTinyInt |
16 |
typeof(byte) |
| Fixed |
adSmallInt |
2 |
typeof(short) |
| Fixed |
adInteger |
3 |
typeof(int) |
| Fixed |
adBigInt |
20 |
|
| Fixed |
adUnsignedTinyInt |
17 |
|
| Fixed |
adUnsignedSmallInt |
18 |
|
| Fixed |
adUnsignedInt |
19 |
|
| Fixed |
adUnsignedBigInt |
21 |
|
| Fixed |
adSingle |
4 |
|
| Fixed |
adDouble |
5 |
|
| Fixed |
adCurrency |
6 |
|
| Fixed |
adDecimal |
14 |
|
| Fixed |
adNumeric |
131 |
|
| Fixed |
adBoolean |
11 |
|
| Fixed |
adError |
10 |
|
| Fixed |
adGuid |
72 |
typeof(System.Guid) |
| Fixed |
adDate |
7 |
Typeof(System.DateTime) |
| Fixed |
adDBDate |
133 |
|
| Fixed |
adDBTime |
134 |
|
| Fixed |
adDBTimestamp |
135 |
|
| Variable |
adBSTR |
8 |
|
| Variable |
adChar |
129 |
typeof(string) |
| Variable |
adVarChar |
200 |
typeof(string) |
| Variable |
adLongVarChar |
201 |
typeof(string) |
| Variable |
adWChar |
130 |
|
| Variable |
adVarWChar |
202 |
|
| Variable |
adLongVarWChar |
203 |
|
| Variable |
adBinary |
128 |
|
| Variable |
adVarBinary |
204 |
|
| Variable |
adLongVarBinary |
205 |
|
So the final code can be something like this: private bool Foo(DataSet rs)
{
try
{
DataColumn dtCol1 = new DataColumn("Value",typeof(string));
dtCol1.AllowDBNull = true;
dtCol1.MaxLength = 1024;
DataColumn dtCol2 = new DataColumn("Name",typeof(string));dtCol2.AllowDBNull = true;
dtCol2.MaxLength = 255;
DataTable dt = rs.Tables.Add();
dt.Columns.Add(dtCol1);
dt.Columns.Add(dtCol2);
return true;
}
catch
{
return false;
}
}
NOTES:
My friend Esteban also told my that I can use C# 3 syntax and write something even cooler like:
DataColumn dtCol1 = new DataColumn()
{
ColumnName = "Value",
DataType = typeof (string),
AllowDBNull = true,
MaxLength = 1024
};
Recently my friend Yoel had just a wonderful idea. We have an old Win32 C++ application, and we wanted to add a serious logging infraestructure so we can provide better support in case the application crashes.
So Yoel came with the idea of using an existing framework for logging: LOG4NET
The only problem was, how can we integrate these two together. One way was problably exporting a .NET object as COM. But Yoel had a better idea.
Create a C++ Managed application that will comunicate with the LOG4NET assemblies, and export functions so the native applications can use that. How great is that.
Well he finally made it, and this is the code of how he did it.
First he created a C++ CLR Empty project and set its output type to Library. In the references we add a refrence to the Log4Net Library. We add a .cpp code file and we call it Bridge.cpp. Here is the code for it:
#include
<atlstr.h>
using
namespace System;
///
<summary>
/// Example of how to simply configure and use log4net
/// </summary>
ref class LoggingExample
{
private:
// Create a logger for use in this class
static log4net::ILog^ log = log4net::LogManager::GetLogger("LoggingExample");static LoggingExample()
{
log4net::Config::BasicConfigurator::Configure();
}public:static void ReportMessageWarning(char* msg)
{
String^ data = gcnew String(msg);
log->Warn(data);
}
static void ReportMessageError(char* msg)
{
String^ data = gcnew String(msg);
log->Error(data);
}static void ReportMessageInfo(char* msg)
{
String^ data = gcnew String(msg);
log->Info(data);
}static void ReportMessageDebug(char* msg)
{
String^ data = gcnew String(msg);
log->Debug(data);
}
};
extern "C"
{_declspec(dllexport) void ReportMessageWarning(char* msg)
{
LoggingExample::ReportMessageWarning(msg);
}
_declspec(dllexport) void ReportMessageError(char* msg)
{
LoggingExample::ReportMessageError(msg);
}
_declspec(dllexport) void ReportMessageInfo(char* msg)
{
LoggingExample::ReportMessageInfo(msg);
}
_declspec(dllexport) void ReportMessageDebug(char* msg)
{
LoggingExample::ReportMessageDebug(msg);
}
}
Ok. That's all. Now we have a managed C++ DLL that exposes some functions as an standard C++ DLL and we can use it with native win32 applications.
Let's do a test.
Lets create a Win32 Console application. And add this code:
// Log4NetForC++.cpp : Defines the entry point for the console application.
//
#include "stdafx.h"
#include <atlstr.h>
extern "C"
{_declspec(dllimport) void ReportMessageWarning(char* msg);
_declspec(dllimport) void ReportMessageError(char* msg);_declspec(dllimport) void ReportMessageInfo(char* msg); _declspec(dllimport) void ReportMessageDebug(char* msg);
}
int _tmain(int argc, _TCHAR* argv[])
{
ReportMessageWarning("hello for Log4NET");
ReportMessageError("hello for Log4NET");
ReportMessageInfo("hello for Log4NET");
ReportMessageDebug("hello for Log4NET");
return 0;
}
Ok. Now we just test it and we get something like:
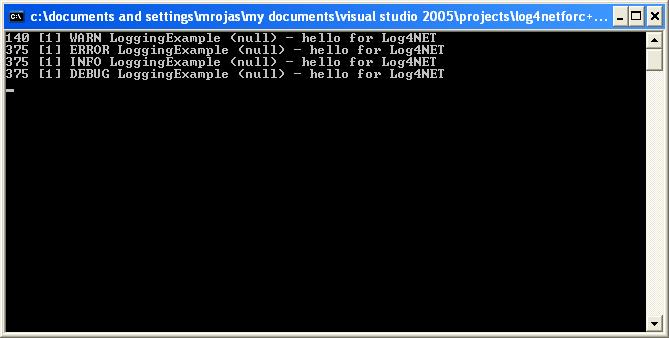
Cool ins't it :)