Console applications are still very useful for me.
I write like 125 console applications in the morning and like 4 or 5 in the afternoon.
In one of these applications that was running a long process I just started wandering:
what will happen with Lost? Will ABC ever finish this series?
And If someone presses Ctrl-C will I be able to catch it?
And indeed, the greate C# provides a very easi way to do it:
static void Main(string[] args)
{ Console.CancelKeyPress +=
delegate(object sender, ConsoleCancelEventArgs e)
{ Artinsoft.VBUMKernel.Implementations.UpgradeCommand.StopAllUpgradeProcess(true);
Console.WriteLine("Process aborted by user!"); };
//Long running process
}
Motivation:
I hate to be disappointed. Specially if it is by a person you had respect for. And that's exactly what Francisco Balena from VB Migration Partner, has done. I have respected him for his books and all his VB6 experience. In terms of legacy VB6 code he is a monster. He is the man.
But in terms of code migration...
I'm not saying this because I work on code migration or maybe I'm biased a little by the fact that I work almost 10 years with a company that has done source code migration research on a big number of legacy languages such as COBOL, RPG, PL\1, Algol, Progress, PowerBuilder and also VB6.
I can tell the difference between a "compiler" and a system that rewrites a expression to the closest equivalent in the target language. We are aware of limitations. We are aware of paradigm differences and functional equivalence, but we talk from experience. We talk about our results. And we have proven those things we talk about.
Let's says you create a Cobol Library with a "MOVE" function, and a COBOLPicture Type and add minus, divide, and add operators. And I write something like:
CobolPicture x = new CobolPicture("XXXX");
x.move(10);
x.add(10);
We have things like that, and it works. It's feasible and maybe there are cases where that is a solution. But we are also proud of have researchers that have been able to detect pattern to rewrite something like that like:
int x = 0;
x = 10;
x+=10;
And saying, that something is not possible just because you can't or you dont like it, just seem uneducated to me.
All of this has motivated me to start a series of chapters I for a small blog book I will call VB Migration (not for the weak of mind).
For those of you, who really are tecnology savvy and are in the process of a VB Migration, this is YOUR book.
Milan Negovan in his blog aspnetresources recently published an excerpt of Michael Feathers' book Working Effectively with Legacy Code. I liked the excerpt so much and I believe that it is so pertinent to the topic of my blog that I also will reproduce it verbatim.
--
Often people who spend time working on legacy systems wish they could work on green-field systems. It’s fun to build systems from scratch, but frankly, green-field systems have their own set of problems. Over and over again, I’ve seen the following scenario play out:
An existing system becomes murky and hard to change over time. People in the organization get frustrated with how long it takes to make changes in it. They move their best people (and sometimes their trouble-makers!) onto a new team that is charged with the task of “creating the replacement system with a better architecture.”
In the beginning, everything is fine. They know what the problems were with the old architecture, and they spend some time coming up with a new design. In the meantime, the rest of the developers are working on the old system. The system is in service, so they receive requests for bug fixes and occasionally new features.
The business looks soberly at each new feature and decides whether it needs to be in the old system or whether the client can wait for the new system. In many cases, the client can’t wait, so the change goes in both. The green-field team has to do double-duty, trying to replace a system that is constantly changing.
As the months go by it becomes clearer that they are not going to be able to replace the old system, the system you’re maintaining. The pressure increases. They work days, nights, and week-ends. In many cases, the rest of the organization discovers that the work you are doing is critical and that you are tending the investment that everyone will have to reply on in the future.
The grass isn’t really much greener in the green-field development.
--
I concord 100% with Michael Feathers. Rewriting code is something that can be achieved only at a very large rate of consumption of time and money! My thesis is that migration, specially automatic migration, is often the best option. You can easily change the platform and then focus on rewriting/rearchitecting only the pieces that truly deserve it. This has been proven over and over again at ArtinSoft.
As anyone attempts to support
migration,
refactoring or related automated
software transformation tasks, some level of
understanding of programs is required, as we might be expecting. The more complex the transformation is the deeper such an understanding could turn to be. Tools like standard compilers stay at the language level; for instance, to translate an “if” statement into alternate sequences of low-level code, independently of what functionality it represents at the application domain. However some migration related tasks usually demand a deeper understanding, for instance when one has to decide that some path of an “if” has to be abstracted as a method for some special domain specific related reason. Thus, a regular compiler translate from a higher into a lower level of semantics, migration tools might also require the opposite direction, in addition. Hence, a measure of understanding capability (
complexity) is involved when dealing with software manipulation.
Naturally, the same is true for human beings, programmers, in usual maintenance labor or more specifically when beginners learn to program. In this last case, some kind of programming exercises help to determine how much understanding the student possesses about the language, an algorithm and its implementation. We might ask ourselves in such a scenario, how complex an exercise could be, how much effort, knowledge and tasks the exercise might involve: A not so easy question that we want to start to investigate, initially in terms of an
e-learning situation for pragmatic reasons. For such a purpose, we have prepared a technical report explaining in more detail the context and some interesting angles of the problem. We invite the interested reader to take a look at the
report.
In the past, the concept of
business continuity was typically associated with a company's ability to
recover from natural disasters (fires, flooding, earthquakes, hurricanes). The
events of September 11th changed the paradigm, ending the somewhat
lax attitude towards business continuity planning and turning attention to
those threats having an element of human intent. Moreover, business continuity
planning began focusing not only on allowing an organization to continue
functioning after and during a disaster, but on reducing its impact, hence
minimizing the risk of extended disruptions.
Undeniably, the traditional
approach to business continuity requirements has shifted, driven by the demands
of globalization and high-tech society. It has grown out of the response and
recovery focus and into prevention strategies and techniques. Under this new
paradigm business continuity emphasizes on managing mission critical business assets
and processes to ensure continuous availability.
Business continuity planning is a
crucial part of an organization's overall risk management, and in a world where
information is power and technology is a decisive business enabler, every analysis
around contemporary threats with a potential of causing severe damage to the
organizational infrastructure leads to the assessment of operational risk linked
to information systems. This certainly recognizes the value of software
assets in today's business infrastructure, taking into account the fact
that significant investments in intellectual capital have usually been embedded
in the systems over the years, comprising the back-bone of many companies.
Therefore, a modern structured approach to managing uncertainty related to
threats encompasses all the necessary averting to ensure reliability, correct
functioning and scalability of business critical applications.
Modern organizations must secure their
continuity considering the increasing complexity and interconnection brought by
the reliance on technology to accomplish their goals. Those with business
critical applications will certainly realize the grave impact of system
malfunction upon business continuity, and the implications for stakeholders of
damage to the organization naturally deems it as unacceptable. Protecting the
financial health and stability of an organization is an essential issue for
management, and the high impact risk associated with vital software
applications make this area of business continuity planning highly relevant on
many companies.
Risk avoidance or reduction strategies linked to information assurance
have to deal with the applications'
security, performance and other technical capabilities, with development and
maintenance costs and support availability constituting critical issues to
consider. In fact, governmental entities and organizations in the power,
telecommunication, health, banking and financial industries are subject to
regulations that aim to protect public interest, including systemic failure
among its previsions to ensure information confidentiality, integrity,
authentication and availability.
But the concept of business
continuity is not limited to regulated public utility infrastructures only. Of
course, it's fairly obvious how some minutes of downtime can seriously affect a
large financial institution, but losing access to information systems has consequences
on any type of business. Business continuity is vital to business success, and in
today's interrelated world, practically every aspect of a company's operation
is vulnerable to fatal disruption. And the aforementioned value of software
assets applies to any type of organization, making it an objectionable
operational risk to maintain exposed, unsupported critical applications that
may not run properly. And modernizing them through non-disruptive methods like automated software migration
effectively contains the issues.
... in fact, a very common question we hear out there when people begin
considering upgrading from VB to .NET: “should I migrate my Visual Basic 6.0
applications to VB.NET or C#?”
Well, Google on the subject and this seems to be an endless
discussion, but let’s start by saying that Microsoft is entirely compromised
with the future of both languages, and they have done great efforts to ensure
that both VB.NET and C# provide the full-power of the .NET Framework. This was
clearly stated during the last TechEd, where I went to both the “Meet the VB
Team” and “Meet the C# Team” sessions. They talked about the future of both
languages, and made clear that there are no riffs between the teams. They even
have Tuesday dinner nights and work together when looking for common solutions.
In fact there are several people working on both teams. Of course, each team
has invested in different features, but this only result in advantages to
developers, providing a better opportunity to opt for the language that better
fits each particular job.
The truth is both VB.NET and C# are first-class citizens on the Common
Language Runtime (CLR) with equal access to the same framework features. So in
the end the decision should be based on your specific needs, that is, your
available resources and customer demands if we are talking about business
applications. For example, if most of your developers have been working with VB
6.0 they will probably feel more comfortable with VB.NET. On the other hand, if
you have a Java or C++ code base coexisting with your VB applications, it might
be better to migrate your VB6 systems to C#, a language that is more
comfortable for programmers exposed to some other object oriented languages due
to its syntax, constructions and usability. However, the real work on a VB6 to
.NET migration is dealing with the Framework and moving your mental model from
COM to .NET, so the transition is not just about syntax and semantics issues.
By the way, we’ve seen a few people suggesting a double path
approach for those who chose to migrate their VB6 applications to C#. This idea
mostly comes from those who offer a solution that only converts to VB.NET, and
they even say it’s irrational to think about jumping from VB6 to any .NET
language other than VB.NET. Well, the immense set of differences between VB6
and C# or VB.NET are accurately resolved by ArtinSoft’s Visual Basic Upgrade
Companion tool, and about half of our customers can tell those unbelievers better.
You’ll find detailed info about that here.
Every once in a while when trying to install the VBUC you may run into error 2869:
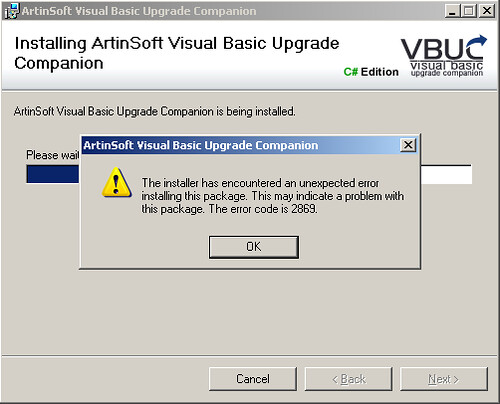
This error, as you can see, doesn't really give you any insight on what may be wrong with the installation. Well, thanks to this blog post, here is a quick process you can follow to troubleshoot the installation and get the actual error that is being masked:
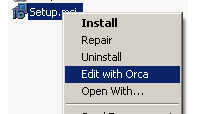
- First, you need to have ORCA installed on your system. ORCA is available as part of the Windows SDK.
- Once you have it installed, find the file setup.msi from the VBUC installer package. Right click on it and select "Edit with ORCA" from the popup menu:
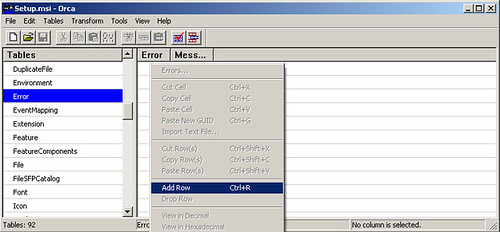
- Once in ORCA, in the Table panel, scroll down and highlight the "Error" line. On the right-hand panel right-click and select Add Row:
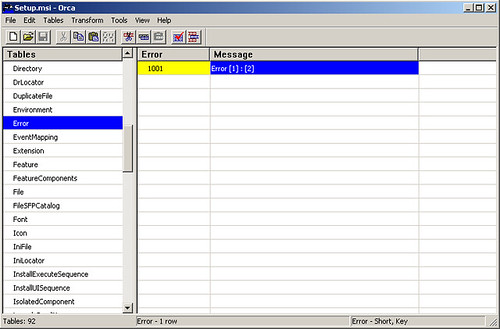
- In the panel that is displayed, enter "1001" for the Error, and "Error [1]:[2]" on the Message. Press OK and the table should look like the following:
- Once you are done editing, save the file in ORCA, close it, and launch the installer. You will now get a more explanatory error:
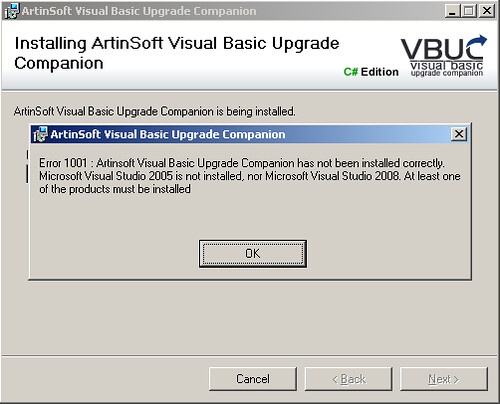
As you can see, in this case at least, the error was caused by not having one of the requirements, Visual Studio (2005 or 2008) installed. This only applies to the current version of the VBUC, as the next version will have these issues with the error messages solved. I still wanted to put this out there, as I got some feedback on it last week.
In our previous post on pattern-matching and ADTs we used Scala for illustrating the idea of pattern extension as a complement to the notion of extractors as defined in Scala (See Post). We want to deepen and discuss some interesting points and derivations related to this requirement that we consider a key one.
By pattern extension we mean the possibility of adding or changing a pattern or combining it with other patterns in different new ways, in other words to have more modularity at this level of the programming or specification language. We know that patterns are available in several (no mainstream) languages however patterns are not usually treated as first-order citizens of such languages. A pattern is usually a sort of notation that the compiler traduces in normal code but not a value in the language. We consider that as an important limitation to the reuse and modularity of application in cases where patterns are numerous as in rule based systems with big amounts of rules. A pattern is actually that important as a query in an information system is, so it is related to a use case and might deserve being handled correspondingly.
Scala provides a nice way to connect patterns with classes as we know. However, Scala does not directly support extensibility at the pattern level as we are figuring out. In this post, we want to illustrate our ideas by developing a simple case using Scala. We want to reify patterns using objects to make the requirement more evident, we exploit many of the facilities that Scala provides but show a limitation we come across as well.
Suppose we want to define our pattern language as an idiom and to have more control over some operational facets of pattern-matching those we might be willing to change or customize. For instance, we would like to code a pattern that matches floating-point values but allows that the pattern matches approximately the muster (with a certain error margin). We want that such functionality would be cleanly a part of a "new" pattern. That is, although things like pattern guards could be used for such a purpose, we want to encapsulate this form of "fuzzy matching" and eventually parameterize it in a class of objects. Notice that for some class of classification problems fuzzy matching can be helpful, hence the example is not completely artificial. Other examples are evidently possible, too. Naturally, if we define our own atomic patterns, we should be able to construct our (boolean) combinations of them, too.
For our purposes, we will define a model of pattern by means of standard OO classes. We assume a very simple protocol (interface) to be satisfied by our family of patterns. We denote this protocol, by the following Scala trait:
trait IPattern[T]{
val value:T
def transduce(e:Any)=e
def matches(e:Any):Option[T] = None
def handle(c:Option[T]) = c
def `:>`(e:Any) = handle(matches(transduce(e)))
}
abstract class AnyPattern extends IPattern[Any]
The matching function is actually located in the method `:>`. The idea is that a pattern is allowed to first transduce the object to match before matching takes place; then the pattern matches the object and finally the "handle" functionality can be added to eventually cope with some particular condition after matching to transducer the result. As seen, we keep the design quite simple according the scope of this post. We assume the transduction does not change the type of neither the object nor the result. Results are given as instances of Scala class Option[T]. The instance field "value" is used by constant patterns those like numbers. We only handle patterns without binding just for simplicity; it can be easily extended for such a purpose.
Now, we can add a wildcard pattern (that matches every object, like _ in Scala)
object TruePattern extends AnyPattern{
val value = null;
override def matches(e:Any):Option[Any] = Some(e)
}
Similarly a class for exact pattern matchin of integers can be defined:
case class IntPattern(val value:Int) extends AnyPattern{
override def matches(e:Any):Option[Int] =
if(value==e) Some(value) else None
}
Let us present our fuzzy pattern for floating point:
case class FloatPattern(val value:Double) extends AnyPattern{
var epsilon:Double=0.01;
private def dmatches(e:Double):Option[Double]={
val diff = Math.abs(value - e );
if(diff<epsilon) return Some(diff)
else return None
}
private def imatches(e:Int):Option[Double]=matches(e.asInstanceOf[Double])
override def matches(a:Any):Option[Double] = a match{
case a:Int => imatches(a)
case a:Double => dmatches(a)
case _ => None
}
}
The pattern accepts integers and values that are at the 0.01 (a default for variable epsilon) distance of the pattern value, a parameter of the pattern. We return as value of the match this difference in absolute value.
As additional examples we define additional pattern combinators (in our algebra of own patterns) for "not", "and" and "or". We show the first two of them, nicely expressible in Scala. Notice that an expression (p `:>` e) produces the matching from pattern p with element e in our notation.
case class NotPattern(val value:AnyPattern) extends AnyPattern{
override def matches(e:Any):Option[Any]= {
val res:Option[Any] = (value `:>` e);
res match {
case Some(_) => return None
case _ => return Some(e)
}
}
}
case class AndPattern(val value:AnyPattern*) extends AnyPattern{
override def matches(e:Any):Option[Any]= {
val res:Option[Any] = Some(e);
for(v <- value){
val res = (v `:>` e);
res match {
case Some(z) => ;
case _ => return None
}
}
return res;
}
}
A guard pattern is also possible too (in this case the value is a Boolean lambda representing the guard):
case class GuardPattern(val value:(Any => Boolean)) extends AnyPattern{
override def matches(e:Any):Option[Unit]={
if(value(e)) return Some()
else return None
}
}
Now, let us add some sugar:
object _Patterns{
def _t = TruePattern;
def _$(x:Int) = IntPattern(x);
def _$(x:Double) = FloatPattern(x);
def _not(x:AnyPattern) = NotPattern(x);
def _and(x:AnyPattern) = AndPattern(x:_*);
def _or(x:AnyPattern*) = OrPattern(x:_*);
def _when(x:Any=>Boolean) = GuardPattern(x);
}
def even(x:Any) = x match{
case x:Int => x%2==0
case _ => false
}
Using this, we might write: _and(_not(_when(even)), _or(_$(1), _$(2)))
to denote a silly pattern that checks for a not even number that is 1 or 2; in other words matches just a 1.
As a final remark, we can be tempted to model these pattern classes adding extractors for representing them as Scala patterns. However, Scala limitations on "objects" (they have to be parameter less) and the "unapply" functions (they are unary) avoid such a possibility. Once again we identify an interesting feature for the language around this limitation.
As a continuation of our previous posts on ADTs, rules and pattern-matching, we go on with our work studying some alternatives to pattern extensibility and generation (see post 1 and post 2). For the extensibility case, we considered delegation by inheritance as an alternative, where we are currently using the programming language Scala for our illustration. In our previous post, we supported the claim the Scala compiler could be able to help in this aspect. In this post we consider pattern generation out from classes, once again, we identify a potential requirement for the programming languages under our study.
In general, we recall our goal is to discover features or their eventual absence in programming languages that give support to an ADT modeling style within a OOP environment. Our motivation and justification comes from the field of automated software transformation (as understood in www.artinsoft.com) and specifically exploring features in languages that properly help to specify transformation rules in a modular and reusable way. The ability to write rules is certainly a central and distinctive element of software transformation tools; especially in the case the feature is available to the final user in order to customize his/her own transformation tasks (as approached for instance in www.aggiorno.com ).
We have already seen how a pattern can be associated with a class in Scala which provides a very natural bridge between rules based programming and OOP. Patterns are views of objects that allow an easy access to its relevant subparts in a particular context, as we know. However, it is programmer’s responsibility to manually build the pattern, in the general case. And knowledge about the set of relevant destructors of the object is required, obviously. And this is usually a matter of domain specific semantics, thus we cope with a task that is difficult to automate.
The notion of destructor is central to ADTs and very particularly when compiling pattern matching. In OOP, destructors are usually implemented as so-called getters (or properties) but, interestingly, neither particular syntax nor semantics in mainstream OOP languages distinguishes them as such from other kind of methods, as we do have for the (class) constructors. In Scala, however, destructors can be automatically generated in some cases which is a fine feature. For instance, consider a simple model for symbolic expressions, defined as follows:
trait ISexp
class Sexp(val car:ISexp, val cdr:ISexp) extends ISexp{
}
class Atom(val value:String) extends ISexp
In this case Scala injects methods for accessing car and cdr fields, thus, in this case destructors are easily recognized. In the case the class would be a case-class the corresponding pattern is indeed generated as indicated by the constructor declaration. But what happens when the class specification is not Scala code or is not given by this explicit way, as in example.
Thus, an interesting question arises if we would want to support semi automated generation of patterns out of classes which are not available in a form that clearly exhibits its destructors.
In ADTs, a destructor is an operator (functor) f that gives access to one parameter of a constructor c. In other words, following invariant should hold in the ADT theory:
Forall x:T: f(c(…, x, ….)) = x
Or if we prefer using an OOP notation:
(new c(…,x,…)).f() = x
In terms of the type system we should have f: () => T where T is the declared type of formal parameter position where x occurs in c.
This provides us with a criterion for guessing candidates for destructors given a class. However, in order to generate code for a pattern, we would need to query the class implementing the ADT looking for such kind of candidates. However, in the case of Scala, we only have reflection as an alternative to perform the required query because there is no code model exposed as class model. Fortunately, the reflection facilities of Java fill the gap. The nice thing is the full interoperability of Scala with Java. The flaw is that we have to generate source code, only.
In order to evaluate the concept, we have developed a very simple Scala prototype that suggests destructors for Java and Scala classes and for generating patterns for such candidates.
For instance, for the classes of the Sexp model given above we automatically get as expected
object Atom {
def unapply(x:sexps.Atom)=Some(x.value)
}
object Sexp {
def unapply(x:sexps.Sexp)=Some(x.car, x.cdr)
}
For a class like java.lang.Integer we get something unexpected:
object Integer {
def unapply(x:java.lang.Integer)=Some(x.intValue, x.toString, x.hashCode)
}
Likewise for the class java.lang.String:
object String {
def unapply(x:java.lang.String)=
Some(x.toCharArray, x.length, x.getBytes, x.hashCode)
}
The overloading of constructors plays at this time an important role on the results. Unfortunately, Scala pattern abstraction does not correctly work if we use overloading for the unapply method. Thus, we have to pack all the possibilities in just one definition. Essential was actually, that we have identified additional requirements which are interesting to get attention as a potential language features.
This is way a discused with a friend for migrating a VB6 RDS CreateRecordset
Private Function Foo(rs As ADOR.Recordset) As Boolean
On Error GoTo Failed
Dim ColumnInfo(0 To 1), c0(0 To 3), c1(0 To 3)
Dim auxVar As RDS.DataControl
Set auxVar = New RDS.DataControl
ColInfo(0) = Array("Value", CInt(201), CInt(1024), True) ColInfo(1) = Array("Name", CInt(129), CInt(255), True)
Set rs = auxVar.CreateRecordSet(ColumnInfo)
Foo = True
Exit Function
Failed:
Foo = False
Exit Function
End Function
According to MSDN the CreateRecordset function takes a Varriant array with definitions for the columns. This definitions are made up of four parts
| Attribute |
Description |
| Name |
Name of the column header. |
| Type |
Integer of the data type. |
| Size |
Integer of the width in characters, regardless of data type. |
| Nullability |
Boolean value. |
| Scale (Optional) |
This optional attribute defines the scale for numeric fields. If this value is not specified, numeric values will be truncated to a scale of three. Precision is not affected, but the number of digits following the decimal point will be truncated to three. |
So if we are going to migrate to System.Data.DataColumn we will used a type translation like the following (for now I’m just putting some simple cases)
| Length |
Constant |
Number |
DataColumn Type |
| Fixed |
adTinyInt |
16 |
typeof(byte) |
| Fixed |
adSmallInt |
2 |
typeof(short) |
| Fixed |
adInteger |
3 |
typeof(int) |
| Fixed |
adBigInt |
20 |
|
| Fixed |
adUnsignedTinyInt |
17 |
|
| Fixed |
adUnsignedSmallInt |
18 |
|
| Fixed |
adUnsignedInt |
19 |
|
| Fixed |
adUnsignedBigInt |
21 |
|
| Fixed |
adSingle |
4 |
|
| Fixed |
adDouble |
5 |
|
| Fixed |
adCurrency |
6 |
|
| Fixed |
adDecimal |
14 |
|
| Fixed |
adNumeric |
131 |
|
| Fixed |
adBoolean |
11 |
|
| Fixed |
adError |
10 |
|
| Fixed |
adGuid |
72 |
typeof(System.Guid) |
| Fixed |
adDate |
7 |
Typeof(System.DateTime) |
| Fixed |
adDBDate |
133 |
|
| Fixed |
adDBTime |
134 |
|
| Fixed |
adDBTimestamp |
135 |
|
| Variable |
adBSTR |
8 |
|
| Variable |
adChar |
129 |
typeof(string) |
| Variable |
adVarChar |
200 |
typeof(string) |
| Variable |
adLongVarChar |
201 |
typeof(string) |
| Variable |
adWChar |
130 |
|
| Variable |
adVarWChar |
202 |
|
| Variable |
adLongVarWChar |
203 |
|
| Variable |
adBinary |
128 |
|
| Variable |
adVarBinary |
204 |
|
| Variable |
adLongVarBinary |
205 |
|
So the final code can be something like this: private bool Foo(DataSet rs)
{
try
{
DataColumn dtCol1 = new DataColumn("Value",typeof(string));
dtCol1.AllowDBNull = true;
dtCol1.MaxLength = 1024;
DataColumn dtCol2 = new DataColumn("Name",typeof(string));dtCol2.AllowDBNull = true;
dtCol2.MaxLength = 255;
DataTable dt = rs.Tables.Add();
dt.Columns.Add(dtCol1);
dt.Columns.Add(dtCol2);
return true;
}
catch
{
return false;
}
}
NOTES:
My friend Esteban also told my that I can use C# 3 syntax and write something even cooler like:
DataColumn dtCol1 = new DataColumn()
{
ColumnName = "Value",
DataType = typeof (string),
AllowDBNull = true,
MaxLength = 1024
};
Recently my friend Yoel had just a wonderful idea. We have an old Win32 C++ application, and we wanted to add a serious logging infraestructure so we can provide better support in case the application crashes.
So Yoel came with the idea of using an existing framework for logging: LOG4NET
The only problem was, how can we integrate these two together. One way was problably exporting a .NET object as COM. But Yoel had a better idea.
Create a C++ Managed application that will comunicate with the LOG4NET assemblies, and export functions so the native applications can use that. How great is that.
Well he finally made it, and this is the code of how he did it.
First he created a C++ CLR Empty project and set its output type to Library. In the references we add a refrence to the Log4Net Library. We add a .cpp code file and we call it Bridge.cpp. Here is the code for it:
#include
<atlstr.h>
using
namespace System;
///
<summary>
/// Example of how to simply configure and use log4net
/// </summary>
ref class LoggingExample
{
private:
// Create a logger for use in this class
static log4net::ILog^ log = log4net::LogManager::GetLogger("LoggingExample");static LoggingExample()
{
log4net::Config::BasicConfigurator::Configure();
}public:static void ReportMessageWarning(char* msg)
{
String^ data = gcnew String(msg);
log->Warn(data);
}
static void ReportMessageError(char* msg)
{
String^ data = gcnew String(msg);
log->Error(data);
}static void ReportMessageInfo(char* msg)
{
String^ data = gcnew String(msg);
log->Info(data);
}static void ReportMessageDebug(char* msg)
{
String^ data = gcnew String(msg);
log->Debug(data);
}
};
extern "C"
{_declspec(dllexport) void ReportMessageWarning(char* msg)
{
LoggingExample::ReportMessageWarning(msg);
}
_declspec(dllexport) void ReportMessageError(char* msg)
{
LoggingExample::ReportMessageError(msg);
}
_declspec(dllexport) void ReportMessageInfo(char* msg)
{
LoggingExample::ReportMessageInfo(msg);
}
_declspec(dllexport) void ReportMessageDebug(char* msg)
{
LoggingExample::ReportMessageDebug(msg);
}
}
Ok. That's all. Now we have a managed C++ DLL that exposes some functions as an standard C++ DLL and we can use it with native win32 applications.
Let's do a test.
Lets create a Win32 Console application. And add this code:
// Log4NetForC++.cpp : Defines the entry point for the console application.
//
#include "stdafx.h"
#include <atlstr.h>
extern "C"
{_declspec(dllimport) void ReportMessageWarning(char* msg);
_declspec(dllimport) void ReportMessageError(char* msg);_declspec(dllimport) void ReportMessageInfo(char* msg); _declspec(dllimport) void ReportMessageDebug(char* msg);
}
int _tmain(int argc, _TCHAR* argv[])
{
ReportMessageWarning("hello for Log4NET");
ReportMessageError("hello for Log4NET");
ReportMessageInfo("hello for Log4NET");
ReportMessageDebug("hello for Log4NET");
return 0;
}
Ok. Now we just test it and we get something like:
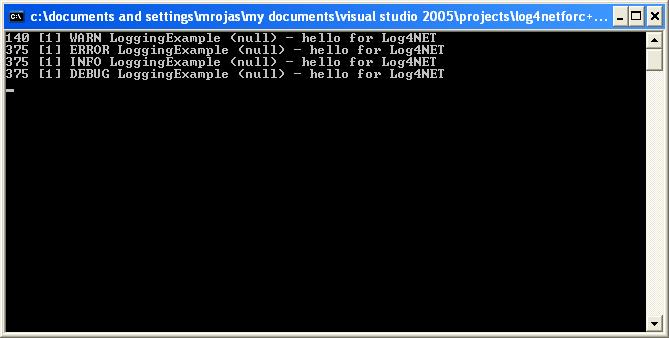
Cool ins't it :)
The latest release of the Visual Basic Upgrade Companion improves the support for moving from VB6.0's On Error Statements to C# structured error handling, using try/catch blocks. In this post I will cover a couple of examples on how this transformation is performed.
First of, this is something that you may not need/want in your application, so this is a features managed through the Migration Profile of the application. In order to enable it, in the Profile, make sure the "On Error To Try Catch" feature is enabled.
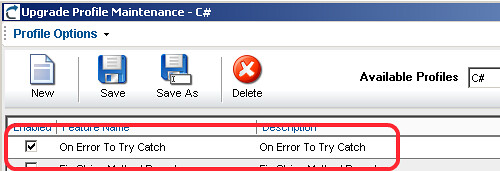
Now let's get started with the examples.
On Error Resume Next
First of, let's cover one of the most frustrating statements to migrate from VB6.0: the dreaded On Error Resume Next. This statement tells VB6.0 to basically ignore errors and continue execution no matter what. VB6.0 can recover from some errors, so an application can continue without being affected. These same errors, however, can cause an exception in .NET, or may leave the application in an inconsistent state.
Now let's look at a code example in VB6.0:
Private Sub bttnOK_Click()
On Error Resume Next
MsgBox ("Assume this line throws an error")
End Sub
The VBUC would then leave it as follows in C#:
private void bttnOK_Click( Object eventSender, EventArgs eventArgs)
{
//UPGRADE_TODO: (1069) Error handling statement
(On Error Resume Next) was converted to a complex pattern which
might not be equivalent to the original.
try
{
MessageBox.Show("Assume this line throws an error",
Application.ProductName);
}
catch (Exception exc)
{
throw new Exception(
"Migration Exception: The
following exception could be handled in a different
way after the conversion: " + exc.Message);
}
}
Because of this, the decision was made to wrap the code that is in the scope of the On Error Resume Next statement on a try/catch block. This is likely the way it would be implement in a "native" .NET way, as there is no real equivalent functionality to tell C# to ignore errors and continue. Also, the VBUC adds a comment (an UPGRADE_TODO), so the developer can review the scenario and make a judgement call on wether to leave it as it is, or change it in some way. Most of the time, the try/catch block can be limited to just one line of code, but that modification requires some manual intervention. Still, it is easier when there is something already there.
:-)
On Error GoTo <label>
The other common scenario is to have a more structured approach to error handling. This can be illustrated with the following code snippet:
Private Sub bttnCancel_Click()
On Error GoTo errorHandler
MsgBox ("Assume this line throws an error")
exitSub:
Exit Sub
errorHandler:
MsgBox ("An error was caught")
GoTo exitSub
End Sub
Since this code is using a pattern that is very similar to what the try/catch statement would do, the VBUC is able to identify the pattern and move it to the appropriate try/catch block:
private void bttnCancel_Click( Object eventSender, EventArgs eventArgs)
{
try
{
MessageBox.Show("Assume this line throws an error", Application.ProductName);
}
catch
{
MessageBox.Show("An error was caught", Application.ProductName);
}
}
As you can see, the functionality of this type of pattern is replicated completely, maintaining complete functional equivalence with the VB6.0 code.
Overall, the support for converting On Error statements from VB6.0 into the proper structured error handling structures in C# has come a long way. It is now very robust and supports the most commonly used patterns. So, unless you are using some strange spaghetti code or have a very peculiar way of doing things, the VBUC will be able to translate most scenarios without issues. Some of them, as mentioned, may still required human intervention, but let's face it - using On Error Resume Next shouldn't really be allowed in any programming language!! ;-)
Ok Ok. I must admitted I have a weird taste to configure my gui. But recently I took it to a the extreme as I (don't know how) delete my File menu.
I managed to get around this thing for a few weeks but finally I fed up. So this gentleman gave me a solution (reset my settings) http://weblogs.asp.net/hosamkamel/archive/2007/10/03/reset-visual-studio-2005-settings.aspx
It’s well known that financial institutions are under a lot
of pressure to replace their core legacy systems, and here at ArtinSoft we’ve seen an increased interest
from this industry towards our migration services and products, specially our Visual Basic Upgrade
Companion tool and our VB to
.NET upgrade services. In fact,
during the last year or so we’ve helped lots of these institutions move their
business critical applications to newer platforms, accounting for millions of
lines of code successfully migrated at low risk, cost and time.
Margin pressures and shrinking IT budgets have always been a
considerable factor for this sector, with financial institutions constantly
looking for a way to produce more with less. Some studies show that most of
them allocate around 80% of their budgets maintaining their current IT
infrastructure, much of which comprised by legacy applications.
Competition has also acted as another driver for legacy
modernization, with organizations actively looking for a competitive advantage
in a globalized world. Legacy applications, like other intangible assets, are
hard to emulate by competitors, so they represent key differentiators and a source
of competitive advantage. Typically, significant investments in intellectual
capital have been implanted in the legacy systems over the years (information
about services, customers, operations, processes, etc.), constituting the
back-bone of many companies.
In the past, they approached modernization in an incremental
way, but recent compliance and security developments have drastically impacted
financial institutions. In order to comply with new regulations, they are
forced to quickly upgrade their valuable legacy
software assets. Industry analysts estimate that between 20-30% of a bank's
base budget is spent on compliance demands, so they are urgently seeking for
ways to reduce this cost so that they can invest in more strategic projects.
However, many institutions manually rewrite their legacy
applications, a disruptive method that consumes a lot of resources, and normally
causes loss of business knowledge embedded in these systems. Hence the pain and
mixed results that Bank Technology News’ Editor in Chief, Holly Sraeel,
describes on her article “From
Pain to Gain With Core Banking Swap Outs”. “Most players concede that such
a move (core banking replacement) is desirable and considered more strategic
today than in years past. So why don’t more banks take up the cause? It’s still
a painful—and expensive—process, with no guarantees”, she notes. “The
replacement of such a system (…) represents the most complex, risky and
expensive IT project an institution can undertake. Still, the payoff can far
exceed the risks associated with replacement projects, particularly if one
factors in the greater efficiency, access to information and ability to add
applications.”
That’s when the concept of a proven automated legacy
migration solution emerges as the most viable and cost-effective path towards
compliance, preserving the business knowledge present in these assets, enhancing
their functionality afterwards, and avoiding the technological obsolescence
dead-end trap. Even more when this is no longer optional due to today’s tighter
regulations. As Logica’s William Morgan clearly states on the interview
I mentioned on my previous post,
“compliance regimes in Financial Services can often dictate it an unacceptable
operational risk to run critical applications on unsupported software”.
“These applications are becoming a real risk and some are
increasingly costly to maintain. Regulators are uncomfortable about
unsupported critical applications. Migrating into the .NET platform, either to VB.NET
or C# contains the issue. Clients are keen to move to new technologies in the
simplest and most cost effective way so that their teams can quickly focus on
developments in newer technologies and build teams with up to date skills”, he
ads, referring specifically to VB6 to .NET migrations.
So, as I mentioned before, ArtinSoft has a lot of experience in large
scale critical migration projects, and in the last year we’ve provided
compliance relief for the financial sector. With advanced automated migration
tools you can license, or expert consulting services and a growing partner
network through which you can outsource the whole project on a fixed time and
cost basis, we can definitely help you move your core systems to the latest
platforms.
We are reviewing some programming languages which provide explicit support for the integration between OO, ADTs (i.e. rules and pattern-matching). We refer to Part 1 for an introduction. We currently focus on Scala and TOM in our work. Scala provides the notion of extractor as a way to pattern-matching extensibility. Extractors allow defining views of classes such that we can see them in the form of patterns. Extractors behave like adapters that construct and destruct objects as required during pattern-matching according to a protocol assumed in Scala. By this way, it results possible to separate a pattern from the kind of objects the pattern denotes. We might consider pattern-matching as an aspect of an object (in the sense of Aspect Oriented Programming, AOP). The idea behind is really interesting, it is clarified in more detail in Matching Objects in Scala . We want to perform some analysis in this post. Our main concern in this part, as expected, is pattern extensibility, we leave the ADT aside just for a while. We will consider a situation where more support for extensibility is required and propose using delegation to cope with it, without leaving the elegant idea and scope of extractors offered by Scala. Pattern-matching by delegation could be more directly supported by the language.
Let us now see the example. Because of the complete integration between Scala and Java, extractors in Scala nicely interact with proper Java classes, too. However, let us use just proper Scala class declarations in our case study, as an illustration. In this hypothetical case, we deal with a model of “beings” (“persons”, “robots”, societies” and the like. We want to write a very simple classifier of beings using pattern-matching. We assume that classes of model are sealed for the classifier (we are not allowed to modify them). Hence, patterns need to be attached externally. We start with some classes and assume more classes can be given, so we need to extend our initial classifier to cope with new kinds of beings.
Thus, initially the model is given by the following declarations (we only have “person” and “society” as kinds of beings):
trait Being
class Person extends Being {
var name:String = _
var age:Int = _
def getName() = name
def getAge() = age
def this(name:String, age:Int){this();this.name=name;this.age=age}
override def toString() = "Person(" + name+ ", " +age+")"
}
class Society extends Being{
var members:Array[Being] = _
def getMembers = members
def this(members:Array[Being]){this();this.members=members}
override def toString() = "Society"
}
We have written classes in a Java-style, to remark that could be external to Scala. Now, let us introduce a first classifier. We encapsulate all parts in a class for our particular purposes, as we explain later on.
trait BeingClassifier{
def classify(p:Being) = println("Being classified(-):" + p)
}
class BasicClassifier extends BeingClassifier{
object Person {
def apply(name:String, age:int)= new Person(name, age)
def unapply(p:Person) = Some(p.getName)
}
object Society{
def apply(members:Array[Being]) = new Society(members)
def unapply(s:Society) = Some(s.getMembers)
}
override def classify(b:Being) = b match {
case Person(n) => println("Person classified(+):" + n)
case Society(m) => println("Society classified(+):" + b)
case _ => super.classify(b)
}
}
object SomeBeingClassifier extends BasicClassifier{
}
Method “classify(b:Being)”, based on pattern-matching, tries to say whether “b” could or not be recognized and displays a message, correspondingly. Notice that objects “Person” and “Society” within class “BasicClassifier” are extractors. In each case, we have specified both “apply” and “unapply” methods of the protocol, however, just “unapply” is actually relevant here. Such methods uses destructors to extract those parts of interest for the pattern being defined. For instance, in this case, for a “Person” instance we just take its field “name” in the destruction (“age” is ignored). Thus, the pattern with shape “Person(n:String)” differs from any constructor declared in class Person. That is, pattern and constructor can be, in that sense, independent expressions in Scala, which is a nice feature.
Now, let us suppose we know about further classes “Fetus” and “Robot” deriving from “Being”, defined as follows:
class Fetus(name:String) extends Person(name,0)
{
override def toString() = "Fetus"
}
class Robot extends Being{
var model:String = _
def getModel = model
def this(model:String){this();this.model=model}
override def toString() = "Robot("+model+")"
}
Suppose we use the following object for testing our model:
object testing extends Application {
val CL = SomeBeingClassifier
val p = new Person("john",20)
val r = new Robot("R2D2")
val f = new Fetus("baby")
val s = new Society(Array(p, r, f))
CL.classify(p)
CL.classify(f)
CL.classify(r)
CL.classify(s)
}
We would get:
Person classified(+):john
Person classified(+):baby
Being classified(-):Robot(R2D2)
Society classified(+):Society
In this case, we observe that “Robot” instances are negatively classified while “Fetus” instances are recognized as “Person” objects. Now, we want to extend our classification rule to handle these new classes. Notice, however, we do not have direct support in Scala for achieving that, unfortunately. A reason is that “object”-elements are final (instances) and consequently they can not be extended. In our implementation, we would need to create a new classifier extending the “BasicClassifier” above, straightforwardly. However, we notice that the procedure we follow is systematic and amenable to get automated.
class ExtendedClassifier extends BasicClassifier{
object Fetus {
def apply(name:String) = new Fetus(name)
def unapply(p:Fetus) = Some(p.getName())
}
object Robot {
def apply(model:String) = new Robot(model)
def unapply(r:Robot) = Some(r.getModel)
}
override def classify(p:Being) = p match {
case Robot(n) => println("Robot classified(+):" + n)
case Fetus(n) => println("Fetus classified(+):" + n)
case _ => super.classify(p)
}
}
object SomeExtendedClassifier extends ExtendedClassifier{
}
As expected, “ExtendedClassifier” delegates parent “BasicClassifier” performing further classifications that are not contemplated by its own classify method. If we now change our testing object:
object testing extends Application {
val XCL = SomeExtendedClassifier
val p = new Person("john",20)
val r = new Robot("R2D2")
val f = new Fetus("baby")
val s = new Society(Array(p, r, f))
XCL.classify(p)
XCL.classify(f)
XCL.classify(r)
XCL.classify(s)
}
We would get the correct classification:
Person classified(+):john
Fetus classified(+):baby
Robot classified(+):R2D2
Society classified(+):Society
As already mentioned, this procedure could be more directly supported by the language, such that a higher level of extensibility could be offered.
Today Eric Nelson posted on one of his blogs a short interview
with Roberto Leiton, ArtinSoft’s CEO.
Eric works for Microsoft UK,
mostly helping local ISV’s explore and adopt the latest technologies and tools.
In fact, that’s why he first contacted us over a year ago, while doing some research
on VB to .NET migration
options for a large ISV in the UK.
Since then, we’ve been in touch with Eric, helping some of his ISV’s move off
VB6, and he’s been providing very useful Visual
Basic to .NET upgrade resources through his blogs.
So click here
for the full interview, where Eric and Roberto talk about experiences and
findings around VB6 to .NET migrations, and make sure to browse through Eric’s
blog and find “regular postings on the
latest .NET technologies, interop and migration strategies and more”,
including another interview
with William Morgan of Logica, one of our partners in the UK.
Abstract (or algebraic) Data Types (ADTs) are well-known modeling techniques for specification of data structures in an algebraic style.
Such specifications result useful because they allow formal reasoning on Software at the specification level. That opens the possibility of automated verification and code generation for instance as we may find within the field of program transformation (refactoring, modernization, etc.). However, ADTs are more naturally associated with a declarative programming languages (functional (FP) and logic programming (LP)) style than an object-oriented programming one (OOP). A typical ADT for a tree data structure could be as follows using some hypothetical formalism (we simplify the model to keep things simple):
adt TreeADT<Data>{
import Integer, Boolean, String;
signature:
sort Tree;
oper Empty : -> Tree;
oper Node : Data, Tree, Tree|-> Tree;
oper isEmpty, isNode : Tree-> Boolean;
oper mirror : Tree -> Tree
oper toString : -> String
semantics:
isEmpty(Empty()) = true;
isEmpty(Node(_,_,_)) = false;
mirror(Empty()) = Empty()
mirror(Node(i, l, r)) = Node(i, mirror(r), mirror(l))
}
As we see in this example, ADTs strongly exploit the notion of rules and pattern-matching based programming as a concise way to specify requirements for functionality. The signature part is the interface of the type (also called sort in this jargon) by means of operators; the semantics part indicates which equalities are invariant over operations for every implementation of this specification. Semantics allows recognizing some special kinds of operations. For instance, Empty and Node are free, in the sense that no equation reduces them. They are called constructors.
If we read equations from left to right, we can consider them declarations of functions where the formals are allowed to be complex structures. We also use wildcards (‘_’) to discard those parts of the parameters which are irrelevant in context. It is evident that a normal declaration without using patterns would probably require more code and consequently obscure the original intention expressed by the ADT. In general, we would need destructors (getters), that is, functions to access ADT parts. Hence, operation mirror might look like as follows:
Tree mirror(Tree t){
if(t.isEmpty()) return t;
return new Node( t.getInfo(),
t.getRight().mirror(),
t.getLeft().mirror() );
}
Thus, some clarity usually could get lost when generating code OOP from ADTs: among other things, because navigation (term destruction, decomposition) needs to be explicit in the implementation.
Rules and pattern-matching has not yet been standard in main stream OOP languages with respect to processing general data objects. It has been quite common the use of regular expressions over strings as well as pattern-matching over semi structured data especially querying and transforming XML data. Such processing tends to occur via APIs and external tools outside of the proper language. Hence, the need for rules does exist in very practical applications, thus, during the last years several proposals have been developed to extend OOP languages with rules and pattern-matching. Some interesting attempts to integrate ADTs with OOP which are worthy to mention are Tom (http://tom.loria.fr/ ) and Scala (http://www.scala-lang.org/ ). An interesting place to look at with quite illustrating comparative examples is http://langexplr.blogspot.com/.
We will start in this blog a sequence of posts studying these two models of integration of rules, pattern-matching and OOP in some detail. We first start with a possible version of the ADT above using Scala. In this case the code generation has to be done manually by the implementer. But the language for modeling and implementing is the same which can be advantageous. Scala explicit support (generalized) ADTs, so we practically obtain a direct translation.
object TreeADT{
trait Tree{
def isEmpty:boolean = false
override def toString() = ""
def mirror : Tree = this
def height : int = 0
}
case class Node(info:Any, left:Tree, right:Tree)
extends Tree{
override def toString() =
"("+info+left.toString() + right.toString()+")"
}
object Empty extends Tree{
override def isEmpty = true
}
def isEmpty(t : Tree) : boolean =
t match {
case Empty => true
case _ => false
}
def mirror(t : Tree):Tree =
t match{
case Empty => t
case Node(i, l, r) => Node(i,mirror(r), mirror(l))
}
}
This code is so handy that I'm posting it just to remember. I preffer to serialize my datasets as attributes instead of elements. And its just a matter of using a setting. See:
Dim cnPubs As New SqlConnection("Data Source=<servername>;user id=<username>;" & _
"password=<password>;Initial Catalog=Pubs;")
Dim daAuthors As New SqlDataAdapter("Select * from Authors", cnPubs)
Dim ds As New DataSet()
cnPubs.Open()
daAuthors.Fill(ds, "Authors")
Dim dc As DataColumn
For Each dc In ds.Tables("Authors").Columns
dc.ColumnMapping = MappingType.Attribute
Next
ds.WriteXml("c:\Authors.xml")
Console.WriteLine("Completed writing XML file, using a DataSet")
Console.Read()
The find in files options of the IDE is part of my daily bread tasks. I use it all day long to get to the darkest corners of my code and kill some horrible bugs.
But from time to time it happens that the find in files functionality stops working. It just starts as always but shows and anoying "No files found..." and i really irritated me because the files where there!!!! !@#$!@#$!@#$
Well finally a fix for this annoyance is (seriously is not a joke, don't question the dark forces):
1. Spin your chair 3 times for Visual Studio 2003 and 4 times for Visual Studio 2005
2. In Visual Studio 2003 press CTRL SCROLL-LOCK and in Visual Studion 2005 press CTRL and BREAK.
3. Dont laugh, this is serious! It really works.
How did ArtinSoft got into producing Aggiorno (www.aggiorno.com )? Well after more than 15 years in the software migration market we learned a few things and we are convinced that developers want to increase their productivity and that automatic programming is a very good mean to do just that.
Aggiorno is the latest incarnation of ArtinSoft proven automatic source code manipulation techniques. This time their are aimed at web developers.
Aggiorno, in its first release, offers a set of key automated improvements for web pages:
- Search engine indexing optimization
- User accessibility
- Error free, web standards compliance
- Cascading Style Sheet standard styling
- Site content and design separation
Aggiorno's unique value proposition is the encapsulation of source code improvements, utterly focused on web developer productivity in order to quickly and easily extend business reach.
At Microsoft TechEd in Orlando this tuesday June 3rd 2008 we announced the availability of Beta2 and we have included all the suggestion from our Beta1.
Download the Aggiorno Beta2 now and let us know what you think.